
REST Client is a Visual Studio Code extension for sending HTTP requests and viewing responses from the productive confines of Code itself.
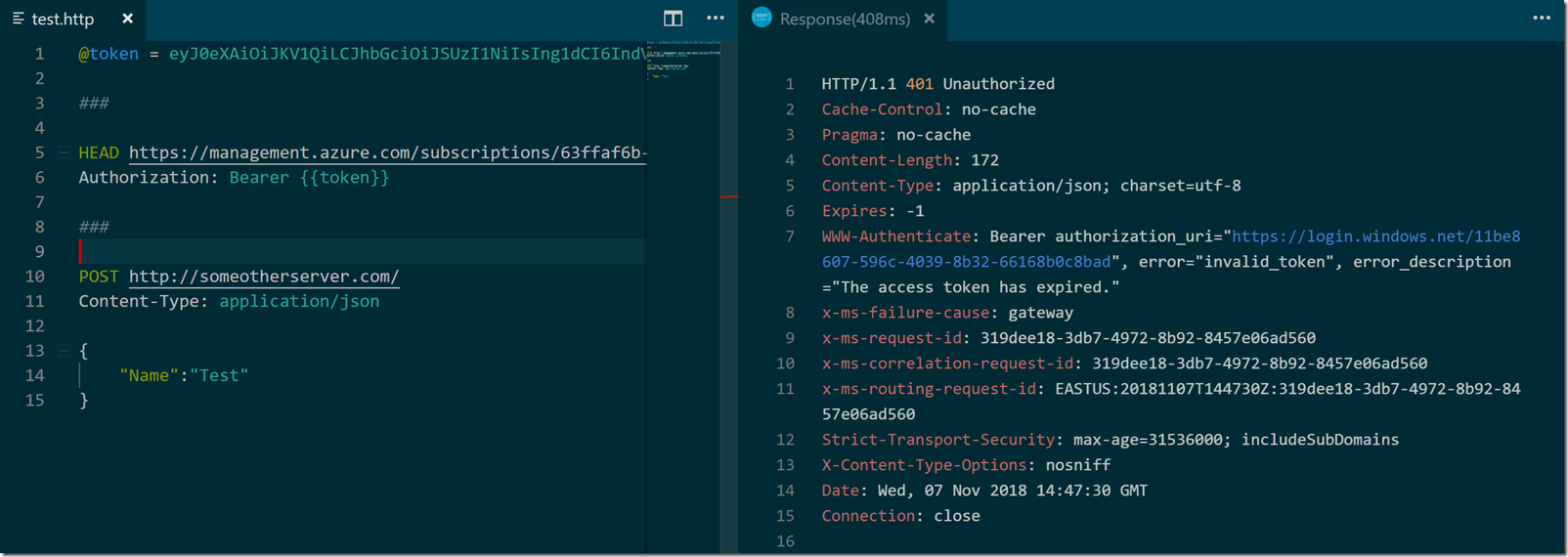
There is no shortage of tools for building HTTP messages, but many of these tools have become unnecessarily complex. I have to select the HTTP method from a tiny drop-down list, enter a header by typing the key and value into two separate inputs, and toggle open a third input to enter the body content. These tools try too hard.
In contrast, REST Client lets me type into an interface designed for creating and editing text – a text editor. I can check-in my experiment to source control, and use standard editor features like search and replace.
On top of all this simplicity, add in REST Client features like variables and the ability to keep multiple requests in the same file and you have a tool that is easy to use and powerful.
Give it a try!
 When I posted 7 Tips for Troubleshooting ASP.NET Core Startup Errors, I thought I had covered every tip needed to track down any possible startup error. In particular, the last step never fails to reveal the culprit.
When I posted 7 Tips for Troubleshooting ASP.NET Core Startup Errors, I thought I had covered every tip needed to track down any possible startup error. In particular, the last step never fails to reveal the culprit.
Then, the last step failed me.
This particular application would not run in an Azure App Service but would run everywhere else - in development, in debug, in release, and in the command line console on the App Service server. How’s that possible?
There is a proverb that says "too many cooks will spoil the broth", meaning when too many people are trying to add their own expertise on the same project, the result will be a disaster. Such is currently the case when two chefs, Visual Studio and the Azure portal, both try to cook a pot of Application Insights.
Application Insights is an invaluable resource for monitoring and troubleshooting an application, but AppInsights has also been a bit flaky to setup with ASP.NET Core in the past. Sometimes AI doesn’t work no matter how hard you try, and sometimes AI does work when you try to make it stop.
Despite the flakiness, AppInsights works great once everything is configured. It is no surprise that both the Azure Portal and Visual Studio encourage the use of AppInsights, but this leads to common questions about the best approach to use AppInsights.
Am I supposed to install the AppInsights NuGet to my project? This "build time" configuration allows an app to use the entire SDK and provide custom telemetry to AppInsights.
Or, am I supposed to setup AppInsights as an Azure App Service extension? This is known as "run-time" configuration and doesn’t require any code changes or new deployments. The official doc uses wording to encourage the "build-time" approach, but you can also find a page that says to use both approaches for the best experience.
The failing application took the "both" approach, and it turns out the "both" approach was the source of the error.
When the application failed with an HTTP 502.5 error, I went to Kudu and ran the app from the console. The application would work from the console, but consistently fail when launched from the worker process in a Windows App Service. This behavior was curious, because both approaches run the same app on the same virtual server with the same file system and the same environment variables. But, decades of debugging experience gave me the insight that something about the environment must be different.
Ultimately I found the true source of the failure by looking at the live stream of the app’s standard output stream.

Even this error was a bit curious since the dotnet publish operation included the required AppInsights assembly in the output. I dug in further and eventually looked at Kudu diagnostics for the w3wp.exe worker process. That’s when the answer jumped out at me.

ASP.NET 2.0 introduced the ASPNETCORE_HOSTINGSTARTUPASSEMBLIES environment variable seen above. The variable allows a host to inject additional startup logic to a compiled application by naming assemblies with IHostingStartup components inside. I had no idea what StartupBootstrapper could be, but a quick search revealed this assembly to be part of the Azure AppInsights extension. In the end, the AppInsights installed by Visual Studio and the AppInsights installed by the Azure extension were incompatible versions. To get the app working, I could do any of the following:
Option #1 seems like the best option, since one might never know when the extension will update and break the application again.
If you think you know exactly what your ASP.NET Core application does during Startup, you could be wrong. IHostingStartup components give platforms an extensibility point to change existing applications, but can also lead to unexpected problems when dependencies conflict. Check for ASPNETCORE_HOSTINGSTARTUPASSEMBLIES if you run into strange startup problems.
It’s not that GUI build tools are bad, per se, but you have to watch out for tools that use too much magic, and tools that don’t let you version control your build with the same zealousness that you use for the source code of the system you are building.
Let’s start with the 2nd type of tool.
Many open source .NET Core projects use AppVeyor to build, test, and deploy applications and NuGet packages. When defining an AppVeyor build, you have a choice of using a GUI, or a configuration file.
With the GUI, you can point and click your way to a deployment. This is a perfectly acceptable approach for some projects, but lacks some of the rigor you might need for larger projects or teams.
You can also define your build by checking a YAML configuration file into the root of your repository. Here’s an excerpt:

Think about the advantages of the source-controlled YAML approach:
You can version the build with the rest of your software
You can use standard diff tools to see what has changed
You can see who changed the build
You can copy and share your build with other projects.
Also note that in the screen shot above, the YAML file calls out to a build script – build.ps1. I believe you should encapsulate as many build steps as possible into a package you can run on the build server and on a development machine. Doing so allows you to make changes, test changes, and troubleshoot build steps quickly. You can use MSBuild, Powershell, Cake, or any technology that makes builds easier. Integration points, like publishing to NuGet, will stay as configurable steps in the build platform.
Azure Pipelines also offers GUI editors for authoring build and release pipelines.
Fortunately, a YAML option arrived recently and is getting better with every sprint.
Magic tools are tools like Visual Studio. For over 20 years, Visual Studio has met the goal of making complex tasks simple. However, any time you want to perform a more complex task, the simplicity and hidden complexity can get in the way.
For example, what does the “Build” command in Visual Studio do, exactly? Call MSBuild? Which MSBuild? I have 10 copies of msbuild.exe on a relatively fresh machine. What parameters are passed? All the details are hidden and there’s nothing Visual Studio gives me as a starting point if I want to create a build pipeline on some other platform.
Another example of magic is the Docker support in Visual Studio. It is nice that I can right-click an ASP.NET Core project and say “Add Docker Support”. Seconds later I’ll be able to build an image, and not only run my project in a container, but debug through code executing in a container.
But, try to build or run the same image outside of Visual Studio and you’ll discover just how much context is hidden by tooling. You have to dig around in the build output to discover some of the parameters, and then you'll realize VS is mapping user secrets and setting up a different environment for the container. You might also notice the quiet installation of Microsoft.VisualStudio.Azure.Containers.Tools.Targets into your project, but you won't find any documentation or source code for thus NuGet package.
I think it is tooling like the Docker tooling that gives VS Code good traction. VS Code relies on configuration files and scripts that can make complex tasks simpler without making customizations and understanding inaccessible. Want to make a simple change to the Visual Studio approach? Don’t tell me you are going to edit the IL in Microsoft’s assembly! VS Code is to Visual Studio what YAML files are to GUI editors.
To wrap up this post in a single sentence: build and release definitions need source control, too.
I’ve completely reworked my secure services course from scratch. There’s a lot of demos across a wide range of technologies here, including:
Building ASP.NET Core projects using Visual Studio and Docker containers.
Deploying container images using Docker Hub and Azure App Services for Linux
Setting up continuous deployment for containers
Using ARM templates to deploy and provision resources in Azure (infrastructure as code)
Setting up Azure Key Vault
Storing secrets in Key Vault for use in ARM templates
Using the new IHttpClientFactory and resiliency patterns for HTTP networking in ASP.NET Core
Container orchestration using Docker compose
Creating and using an Azure Container Registry (ACR)
Deploying multiple images using ACR And Compose
Creating your own test instance of Azure Active Directory
Authentication with OpenID Connect (OIDC) and Azure Active Directory
Securing APIs using Azure Active Directory and JWT tokens
Invoking secure APIs
Setting up an Azure B2C instance and defining your own policies
Securing an application using Azure B2C.
Note: this updated course is an hour shorter than the original course. Pluralsight authors generally want to make courses longer, not shorter, but I learned how to tell a better story this second time around. Also, the Docker story and tooling is markedly improved from last year, which saves times.
I hope you enjoy the course!
Previously, we looked at some folders to include in your source code repository. One folder I didn’t mention at the time is a deployment folder.
Not every project needs a deployment folder, but if you are building an application, a service, or a component that requires a deployment, then this folder is useful, even if a deployment is as simple as copying files to a well-known location.
What goes into the folder?
At one extreme, the folder might contain markdown instructions about how to setup a development environment, or a list of prerequisites to develop and run the software. There’s nothing automated about markdown files, but the developer starting this week doesn’t need to figure out the setup using trial and error.
At the other extreme, you can automate anything these days. Does a project need specific software on Windows for development? Write a script to call Chocolatey. Does the project use resources in Azure for development? The Azure CLI is easy to use, and Azure Resource Manager templates can declaratively take on some of the load.
Ruthlessly automating software from development to production requires time and dedication, but the benefits are enormous. Not wasting time on setup and debugging misconfigurations is one advantage. Being able to duplicate a given environment with no additional work comes in handy, too.
"Cloud Computing Governance" sounds like a talk I’d want to attend after lunch when I need an afternoon nap, but ever since the CFO walked into my office waving Azure invoices in the air, the topic is on my mind.
It seems when you turn several teams of software developers loose in the cloud, you typically set the high-level priorities like so:
Missing from the list is the priority to "make the monthly cost as cheap as possible", but cost is easy to overlook when the focus is on security, quality, and scalability. After the CFO left, I reviewed what was happening across a dozen Azure subscriptions and I started to make some notes:
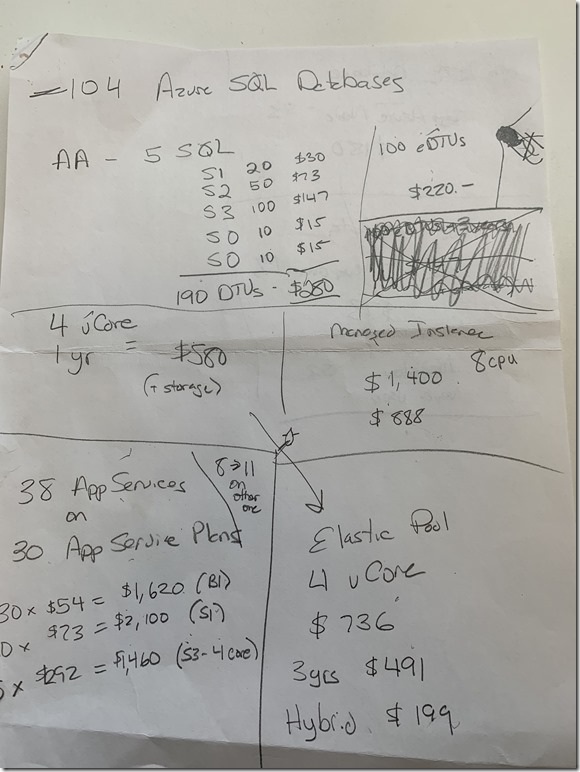
Yes, there’s 104 un-pooled Azure SQL instances, and 38 app services running on 30 app service plans.
There are countless people in the world who want to sell tools and consulting services to help a company reduce costs in the cloud. To me, outside consultants start with only 1 of the 3 areas of expertise needed to optimize cost. The three areas are:
In Venn diagram form:
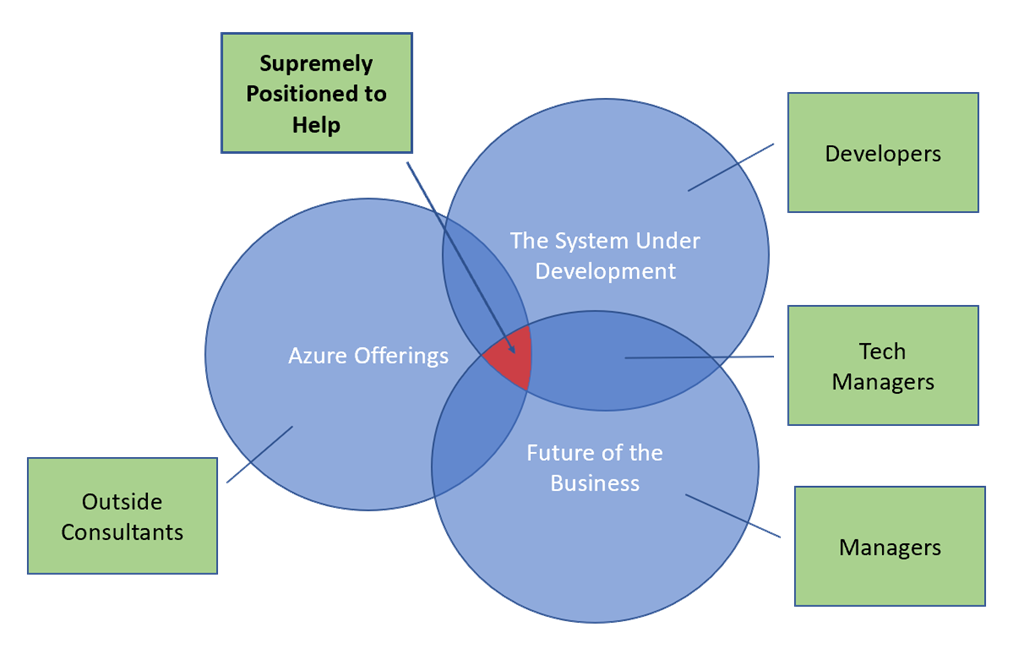
Let’s dig into the details of where these three areas of knowledge come into play.
Let’s say your application needs data from dozens of large customers. How will the data move into Azure? An outside consultant can’t just say “Event Hubs” or “Data Factory” without knowing some details. Is the data size measured in GB or TB? How often does the data move? Where does the data live at the customer? What needs to happen with the data in the cloud? Will any of these answers change in a year?
Without a good understanding of the Azure offerings, a tech person often answers with the technology they already know. A SQL oriented developer, for example, will use Data Factory to pump data into an Azure SQL database. But, this isn’t the most cost effective answer if the data requires heavy duty processing after delivery, because Azure SQL instances are priced for line of business transactions that need atomicity, reliability, redundancy, high availability, and automatic backups, not hardcore compute and I/O.
But let’s say the answer is SQL Server. Now what?
Now a consultant needs to dig deeper to find out the best approach to SQL Server in the cloud. There are three broad approaches:
Option #1 is best for lift and shift solutions, but there is no need to take on the responsibility for clustering, upgrades, and backups if you can start with PaaS instead of IaaS. Option #2 is also designed for moving on-prem applications to the cloud, because a managed instance has better compatibility with an on-prem SQL Server, but without some of the IaaS and management hassles. For greenfield development, option #3 is the best option for most scenarios.
Once you’ve decided on option 3, there is another two levels of cost and performance options to consider. It’s not so much that Azure SQL is complicated, but Microsoft provides flexibility to cover different business scenarios. For any given Azure SQL instance, you can:
Option #1 is the best option when you manage a single database, or you have a database with unique performance characteristics. A pool is usually better from a cost to performance ratio when you have 3 or more databases.
After you’ve decided to pool, the next decision is to decide how you’ll specify the performance characteristic of the pool. Will you use DTUs? Or will you use vCPUs? DTUs are frustratingly vague, but we do know that 20 DTUs are twice as powerful as 10 DTUs. vCPUs are at least a bit familiar, because we equated CPUs with performance capability for decades.
One significant difference between the DTU model and the vCPU model is that only the vCPU model allows for reserved instances and the “hybrid benefit”. Both of these options can lead to huge cost savings, but both require some business knowledge.
The “hybrid benefit” is the ability to bring your own SQL Server license. The benefit is ideal for moving SQL databases from on-prem to the cloud, because you can make use of a license you already own. Or, perhaps your organization already has a number of free licenses from the Microsoft partner program, or discounted licenses from enterprise agreements.
Reserved instances will save you 21 to 33 percent if you commit to a certain level of provisioning for 1 to 3 years. If you customers sign one year contracts to use your service, a one year reserved instance is a quick cost savings with little risk.
If everything I’ve said so far makes it sound like you could benefit from a using a spread sheet to run hypothetical test, then yes, setting up a spreadsheet does help.
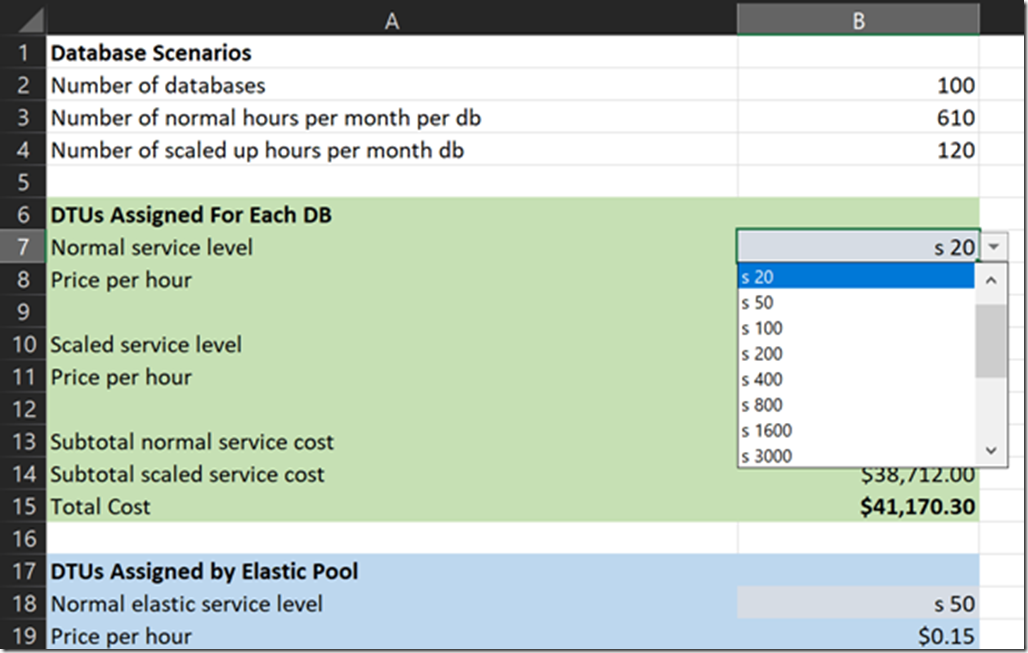
Once you have a plan, you have to enforce the plan and reevaluate the plan as time moves forward. But, logging into the portal and eyeballing resources only works for a small number of resources. If things go as planned, I’ll be blogging about an automated approach over the next few months.
I’ve updated my Cloud Patterns and Architecture course on Pluralsight.
The overall goal of this course is to show the technologies and techniques you can use to build scalable, resilient, and highly available applications in the cloud, specifically with Azure.
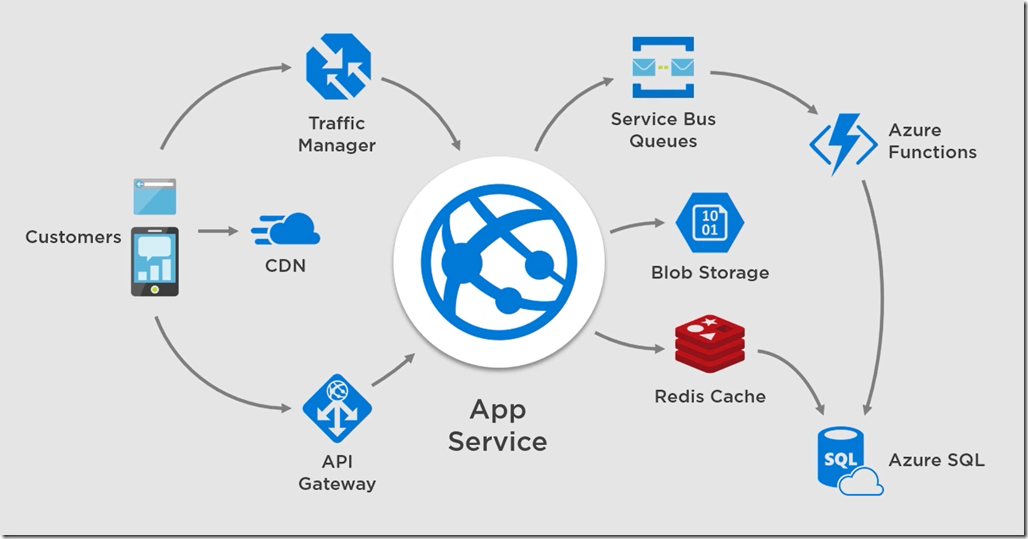
In addition to walking through sample architectures, demonstrating design patterns, and adding bits of theory on topics like the CAP theorem, here are some of the lower level demos in the course:
Setting up Azure Traffic Manager and using Traffic Manager profiles to route traffic to a geo-distributed web application.
Setting up Azure Service Bus to send and receive queued messages.
Creating an Azure Redis Cache and using the cache with an SDK, as well as configuring the cache to operate behind the ASPNET IDistributedCache interface.
Provisioning a Content Delivery Network (Azure CDN) and pushing static web site content into the CDN.
Importing a web API into Azure API Manager using OpenAPI and the ASPNET Swashbuckle package, then configuring an API to apply a throttling policy.
Creating, tweaking, running, and analyzing load tests using Azure DevOps and Visual Studio load testing tools.
And more! I hope you enjoy the course!

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#