
Yes, ASP.NET MVC 5 Fundamentals is a new course, made from scratch, and made with care.
I’ve been asked why I’m taking the time to make courses on frameworks that are old and out of fashion. The answer is because an extraordinary number of extraordinary people work with this legacy framework, and my existing MVC 5 course was out of date. As the author of several legacy-but-still-revenue-generating web forms applications, I have a soft spot for developers who aren’t working with the latest and greatest technologies. This new MVC 5 course is for those developers who quietly keep the lights on in the world.

.NET Core opinions are returning from a summer holiday in time to brave the melancholia of autumn.
ASP.NET Core 2.0 introduced Razor Pages, which I believe are superior to the MVC framework when building HTML applications with .NET Core.
Razor Pages encourage a separation of concerns in presentation layer logic, just as the MVC framework does. Razor pages also follow patterns like dependency injection that promote flexibility and testability. But, Razor Pages also offer clear advantages over MVC when generating HTML and processing forms on the server.
Razor Pages encourage developers to remain constrained in the number of features they add to a class. With pages, you typically pick a specific feature to implement using only GET and POST methods, while controllers can grow to implement dozens of different actions.

It was easy to see the overstuffed controller phenomenon when using the ASP.NET Identity framework. The Razor Pages version of ASP.NET Identity (shown below on the left) makes it easy to find specific features because the pages are granular. The controller version uses only two controllers with dozens of assorted actions inside. It’s worth noting that the ASP.NET Identity project now supports only Razor Pages when scaffolding a UI.
Imagine trying to find the functionality to change a password in the application. With Razor Pages it is easy to spot the page, while the controller approach hides the feature inside a mega-controller with views and models scattered across other directories.
Speaking of feature organization, I’ve always been a fan of feature folders with the MVC framework. The MVC design pattern wants us to separate concerns using controllers, views, and models. But, nothing in the MVC framework says the models, views, and controllers need to be physically separated into distinct files and spread across separate directories. One of the more frustrating aspects of working with MVC, other than HTML helpers, was trying to track down all the files I need to open when working on a specific feature.
Razor pages maintain a separation of concerns without spraying code across the file system. The page code functions like a controller while the page view contains the presentation logic. You’ll find the code file and the view file nested together. Models and view models can live anywhere but are typically exposed as direct properties of the page, so all the pieces are easy to find.
public class DetailModel : PageModel
{
private readonly LeagueData leagueData;
public int SwanCount = 59;
public Season Season { get; set; } = new Season();
public DetailModel(LeagueData leagueData)
{
this.leagueData = leagueData;
}
public void OnGet(int id)
{
var query = new SeasonDetailQuery(id);
Season = leagueData.Execute(query);
}
}
Anecdotal evidence tells me that applications built with Razor pages have better URL structures than apps with controllers. Controller apps tend to overuse the default routing template, which leads to a flat URL structure and lots of controller actions taking an ID parameter. Razor pages, on the other hand, tend to promote the organization of related pages into subfolders. Given that ASP.NET Core derives a page URL from the page’s physical location, the URLs are hierarchical and better describe the different features and regions of an application. It’s also easy to look at the UI, and find the Razor page responsible for a particular screen.
Razor pages have a lot to offer, including features I haven’t detailed yet, like automatic anti-forgery token validation.
There are also features that do not exist in Razor pages, despite what the ill-informed say.
There is no viewstate in Razor pages. There are also no synthetic initialize or click events. A Razor page is no more stateful than a controller with it’s ModelState data structure. In short, Razor Pages aren’t related to Web Forms or Web Matrix Web Pages. Razor pages are an authentic abstraction for programming the web.
Razor Pages are a welcomed refinement to the MVC framework and include many optimizations for sever-side HTML generation and form processing. Try them out before rushing to judgment!
The need to use the MVC framework is fading into the background with ASP.NET Core. Instead of MVC, we have Razor Pages for HTML apps, Controllers for 'REST' APIs, gRPC services for coupled APIs, and SignalR for real time communications.
A classic question in software is "are we done yet?". This is not just a question for software developers. Anyone who is working in IT needs to ask the question when writing code, testing a feature, upgrading a network, or designing a user experience.
There is no perfect answer to the question. Every individual, every team, every business scenario will have a different answer, and you’ll only know if the answer was good using hindsight.
However, we need to make sure we ask the question and think about the answer.
Most of us work in a business that wants to move fast. We feel a lot of pressure to release software as quickly as possible and move on to the next task. We descend on tasks like peregrine falcons - moving quickly and finishing jobs at breakneck speeds.

There’s a danger in moving too fast. We take shortcuts, we rely on short term thinking, and we accumulate technical debt. Moving too fast today will force us to go slower tomorrow. We’ll spend more time tracking down bugs that are hard to find, and it takes longer to make changes in brittle code.
We need to avoid future slowdowns by moving at a sustainable pace. A sustainable pace requires us to change our definition of "done".
Most teams tend to focus on functional requirements. A functional requirement is how we think about the behavior of a system. For example – "must import an HL7 XML file", or "must compute the customer discount". A job can’t be done until the functional requirements are satisfied.
A business might also include some non-functional requirements. Non-functional requirements describe a specific characteristic or quality of a system. For example – "must comply with U.S. section 508 accessibility laws", or "must maintain a median response time less than 3 seconds".
Good development teams will go beyond just the requirements handed over by the business. Here are three specific non-functional requirements that we often sacrifice so we can move faster. However, without these requirements we are going to move slower in the future. The pace is unsustainable.
We need to build maintainable software. The code we write today might be around for many years. I have a 20-year old web forms application still in production. We need to make sure code is clean and, in the right places, extensible.
Most clouds makes it easy for one developer to publish software into a platform. Unfortunately, it then becomes easy for the entire team to think of the one developer as The Person Who Does Every Install and never bother with automating the install so that anyone can deploy the software at any time. The irony here is that DevOps platforms and cloud themselves have never been so easy to automate. Good teams will automate every step ruthlessly.
Nothing is more time consuming than bugs that leave behind no clues. Instead of fixing problems, teams can spend days hypothesizing about what could be going wrong. Today's micro-service architectures with distributed messages make the scenarios even more difficult. There are, however, good solutions. Teams have to take the time to make software observable, and use telemetry frameworks that know how to correlate cross-process activities.
Most of us should say our software isn’t good enough for the first release into production until it is maintainable, deployable, and observable. To achieve these goals we want to:
Schedule more regular design and code reviews.
Automate deployments to the point where someone who is not on the team can deploy the app with a minimum amount of instruction.
Include error scenarios in test plans. Users should see friendly error pages with a transaction code they can capture. Errors in any page, controller, form, or API endpoint needs to generate diagnostic information in a queryable data source.
Here are some questions, with answers, from my interview session at Pluralsight LIVE!.
I was working for a Microsoft shop when Microsoft first released .NET. At the time I was writing COM components in C++. I read about .NET in MSDN magazine, which is defunct now, sadly, but I wanted to be the first person at my company to understand .NET and be able to lead the charge in a new direction.

The .NET ecosystem has always been a good ecosystem, although there were some dark days when Silverlight died, and Sinofsky announced the Win8 development stack, which made no mentions of .NET. I'm happy the ecosystem is back and healthier than ever. Teams inside Microsoft embrace .NET Core, and we are seeing a .NET renaissance.
I’ve stayed here because the ecosystem is familiar, yes, but also exciting again. .NET is also not as fragmented and disjointed like other ecosystems, and I still think .NET has the best tools and can be the most productive.
I hope development teams embrace non-nullable reference types. I’ve been using non-nullable references in a new project, and I’m seeing why developers rave about languages, like F#, where you don’t have to spend as much time reasoning about nulls. You might have to work a bit harder at first, but there’s a certain amount of complexity that disappears from your thinking, and from the code itself.
The reoccurring hurdle in my career has been data. If only we could write software without worrying about data! I’ve always worked on projects where even getting to the data is a challenge. Real data is always dirty and messy, so one tough job is cleaning up data for the software to work.
Another reoccurring hurdle has been mapping data. I've spent most of my time in the mortgage industry and the healthcare industry, and in both places there is always difficulty in moving data from one system to another. You need to change identifiers and lookup codes. You also need to change the shape of the data, sometimes matching two pieces together, sometimes splitting one piece apart.
Another hurdle is the volume of data, especially these days. How do you move large datasets from one source to another? I feel there is an iron triangle in the extract, load, and transform operations. You can be flexible. You can be fast. You can be cheap. But, you can only pick two of those three qualities.

I don't think I've ever overcome the data hurdle, so to speak. Software is about tradeoffs. For the complex problems in real-world software you'll never find perfect solutions. What you hope to find is a solution that removes some of the problems you want to avoid, and gives you a set of problems you are willing to deal with.
A good example is picking a database technology. Do you need flexibility in how to evolve the schema? Pick a document database, but understand the problems you'll face with reporting and aggregations. Does the business require strict consistency? Pick a relational database, but understand the challenges you'll face in scalability and object-relational mapping. Want the best of both worlds? Send your writes to a relational database and query from a document database, but understand the new set of problems stemming from the additional complexity of maintaining two data stores. Software is all about tradeoffs!
I need to be hands on. I’ll give you a recent example where I was gearing up to learn Apache Spark. I read quite a bit about Spark at high level. I watched some videos. I browsed some blog posts. I understood the types of problems Spark is trying to solve and how Spark relates to other technologies like Hadoop. But, I learned more about Spark in 30 minutes after I installed the software locally and worked through some examples in the Spark shell, which is like a REPL for Spark.
By the way, REPLs are always avfantastic tool for learning and exploring a technology or language.

Have patience and be persistent! Something I’ve realized over the years is how much I continue to learn about technologies I think I already know as time passes. I believe the learning happens because my perspective changes over time and I can see the technology in a different light.
An example would be delegates in C#. I found delegates to be confusing and difficult to learn when I started with C#, and based on what I hear from my students, this is true for nearly everyone. Over the years I learned about other languages, like Python and Ruby and JavaScript, where functions are first class. I began to see past the complicated C# syntax for delegates and understand some of the simple functional concepts that form the basis of delegates. You could say my experience gave me a brighter light to shine on the subject of delegates so I could see them clearly for what they are, and what they are capable of.
If you feel like you are stuck on a topic, try approaching the topic from a different direction. Try to solve a different problem with the technology, or try a different technology with the same problem. The range of experiences you can gather will help you gain the insights you need, but experience takes time. Learning is a marathon race, and not a sprint.
Without a doubt the best change is the move towards ethical computing and ethical software. I feel fortunate and privileged to have grown up in the golden age of computing, where every day, and every month, and every year computers grew more powerful and made positive impacts in my life. For example, if I think back to the first time I came here to Salt Lake city, it was in the days before the iPhone. I had to rent a car, and look at a map to plan my drive from the airport. I spent lots of time and money just managing the logistics of the trip.
Yesterday, I flew into the airport with no preparation and used my phone at baggage claim to book a $15 ride to the hotel. Technology boosted my productivity all through the trip, and removed a lot of stress.

I worry that in the future I might have grandkids and they won't see computers as powerful and fun. I worry they might see computers as tools of oppression, or depression. I believe it was Scott Galloway that said something like social media is to mental health what smoking was to the physical health of our parent's generation. In other words, when I was growing up,I remember seeing the magazine ads with the Marlboro man and marketing copy about all the pleasures of smoking. Smoking was cool and doctor approved! Most people today understand the physical tolls of smoking on the respiratory and cardiovascular systems. Smoke is a poison. I genuinely worry that future generations will look back at social media's impact on mental health in the same light, and maybe even the Internet in general. The unlimited content, the unlimited conflict, and the AI algorithms designed to feed us dopamine boosts to keep us hooked – these are all pushing into dangerous boundaries.
I still think Angular 1.5 was the best version of Angular. Yes, Angular in the v1 days had quirks, and a strange vocabulary, and was not the easiest framework to learn. But, Angular was an amazingly productive framework once you got over the initial hurdles.
Speaking of mental health, I walked away from front-end development about 20 months ago. I feel much more relaxed these days.
If you are in front end development, or the JavaScript ecosystem in general, the one thing I would say is to make sure you learn the timeless skills. Yes, to do the best work you’ll need to know your framework, your language, and the operating environment. You'll need to know it all cold. But, there are diminishing returns to this learning path because the technologies here are ephemeral and what you'll need in 5 years will be different.
Timeless skills would be skills like designing a user experience, or writing clean code as a craft, or leading a software team. Those skills are still valuable in 5, 10, 20 years.
Azure DevOps amazes me. I have always been someone who promotes and works toward good configuration management practices. I once wrote a custom build engine so the company could have a repeatable build and release process. We could check-in source code to start a build, and have the build package the software for deployment. This was 18 years ago. That system was a lot of work, but a lot of fun to build and gave us many advantages.
Eventually Microsoft’s Team Foundation Server replaced the system, but TFS was also a lot of work to install, configure, and maintain. DevOps makes it so easy to setup a source code repository, define a build, define a release, and track work items. I don’t have to spend time on infrastructure problems or worry about upgrades.

I think we will see more serverless platforms, or, more of the existing platforms move to a serverless model. The word serverless is thrown around too much as a marketing term, though, so let me be more specific. I think we will continue to move to a model in the cloud where we pay for what we use instead of paying for what we provision. That’s what serverless means to me.
I want to tell Azure here is my code, and here is my data. Now, if I have 1,000 customer requests tomorrow bill me $1 for the day. And, if there are 10,000 requests the day after bill me $10 for the day. Then, if there are one million requests the next day, bill me $100. I don’t want to define what type of service plan I need and then setup and configure auto-scale rules. I don’t want to pay to reserve the virtual hardware for 2 million requests and then only have 1 customer show up. All this AI power in the cloud should give me what I need just in time.
I’ve never been particularly good at predicting software futures, but I do think the pressures of ethical computing will continue to grow. As software developers we are accustomed to attending family reunions and trying to avoid those relatives who want us to fix their PC, or hook up their printer, or help them download pictures from their flip phone.
I’m worried we are going to start avoiding those relatives who ask us harder questions. Like, why did bad software allowed their identity to be stolen, or my car to avoid an emission test, or crash an airplane, or discriminate against individuals. I think we need to start using tools like the Ethical operating system, which is a toolkit for evaluating risk zones to help you think about the long term ethical impacts of software.
I mentioned this before, but the first truth is that a career in software development is a marathon, not a sprint. You want to make sure you are continually improving and at a steady pace. It will take some time, but you can be as great as you will yourself to be.
The second truth I wish I knew when I started is that empathy is crucial for software development. If you are a developer who builds a UI, you need to have empathy for the users of your user interface. If you are a developer building a web service, you have to have empathy for the users of your API. When you are writing any line of code, you need to have empathy for the other developers who come along to maintain or change your code. You also need empathy for the ops team. How can you make your software easier to deploy? How can you make your software easier to monitor and troubleshoot when the software is in production?
I can’t overemphasize empathy, and I believe empathy is a skill you can improve. Get to know the people who use your code, who use your software, who operate your software. Get out of your comfort zone and try to experience other people’s viewpoints and opinions.
And finally, hone your ability to do root cause analysis. This will help you not only in software development, but also in your personal relationships, your business relationships, your health, your leadership abilities, and in so many places in life. Learn how to ask the 5 whys. The 5 whys are a good process you can use to start practicing root cause analysis, and you can practice on everyday problems you face in life.
I've been working with Apache Spark recently, and i find it absolutely fascinating. I think the ability to apply functional programming techniques to distributed computing and large datasets is fascinating and exciting. For .NET developers, think of it as LINQ for big data. Maybe I'll be able to put together a course for .NET developers who need to use Spark.
Let’s say you are working in the kitchen and preparing a five-course meal. A five-course meal is a considerable amount of work, but fortunately, you have an assistant who can help you with the mise en place. You’ve asked your assistant to cube some Russet potatoes, julienne some baby carrots, and dice some red onions. After 15 minutes of working, you check on your assistant’s progress and ...

What a disaster! You have diced onions to cook with, but you’ve also got a mess to clean up.
This is how I feel when I use a method with the following inside:
return null
I’m seeing thousands of return null statements in recent code reviews. Yes, I know you’ll find my fingerprints on some of that code, but as my mom used to say: "live and learn".
An ideal function, like an assistant cook, will encapsulate work and produce something useful. A function that returns a null reference achieves neither goal. Returning null is like throwing a time bomb into the software. Other code must a guard against null with if and else statements. These extra statements add more complexity to the software. The alternative is to allow null to crash the program with exceptions. Both scenarios are bad.
Before throwing in a return null statement, or using LINQ operators like FirstOrDefault, consider some of these other options.
In some scenarios the right thing to do is to throw an exception. Throwing is the right approach when null represents an unrecoverable failure.
For example, imagine calling a helper method that gives you a database connection string. Imagine the method doesn’t find the connection string, so the method gives up and returns null. Your software doesn’t function without a database, so other developers write code that assumes a connection string is always in place. The code will try to establish connections using null connection strings. Eventually, some component is going to fail with a null reference exception or null argument exception and give us a stack trace that doesn’t point to the real problem.
Instead of returning null, the method should throw an exception with an explicit message like "Could not find a connection string named 'PatientDb'". Not only does the software fail fast, but the error message is easier to diagnose compared to the common null reference exception.
Throwing is not always the right option, however. Consider the case where a user is searching for a specific patient using an identifier. A method to execute the search has to consider the possibility that a user is searching with a bad or obsolete identifier, and not every search will find a patient. In this scenario it might be better to return null than throw an exception. But, there are other options, too.
Finding a sensible and safe default value works in some scenarios. For example, imagine a helper method to fetch the claims for a given user. What should the method do when no claims are found? Instead of returning null and forcing every caller to guard against a null collection of claims, consider returning an empty collection of claims.
private static readonly IReadOnlyDictionary<string, string> EmptyClaims = new Dictionary<string, string>();
public IReadOnlyDictionary<string, string> FindClaims(int userId)
{
/*
* Find claims from somewhere, or ...
*/
// when no claims are found . . .
return EmptyClaims;
}
If callers only use ContainsKey or TryGetValue to make authorization decisions, the empty claims collection works well. There are no claims in the empty collection, so the software will never authorize the user. Even better, the code doesn’t need to guard against a null reference.
Think of all the complexity you've removed from the rest of the software! Future generations who work on the code will praise you and build ornate shrines in your honor.
The null object pattern has been around for a long time because the pattern is successful at reducing complexity and making software easier to read and write. Imagine a method that needs to return the current user in the system, but the method can’t identify the user. Perhaps the method can’t identify the user because the user is anonymous, and not being able to find the user is an expected condition. We shouldn’t handle an expected condition using exceptions.
Another option is to use null to represent an unknown user, but returning null is lazy. In case you missed the opening paragraphs, returning null is like telling your callers "I’m not only giving up, but I’m going to stick you with a dangerous value, so handle with care, and good luck!". Future generations who work on the code will curse you and burn you in effigy.
The null object pattern solves the problem by returning a real object reference, and the real object contains some safe defaults. We don’t want an unidentified user to gain access to admin functionality, or somehow slip through permission checks, so we create a version of the user that will fail all permission checks and not display a name, but at the same time no code needs to guard against null and introduce if else checks everywhere.
There are a number of different approaches you can use to design null objects, but remember the goal is to build an object with safe defaults. Here’s an example. Let’s start with a User type.
public class User
{
public User(string name, IReadOnlyDictionary<string, string> claims)
{
Name = name;
Claims = claims;
}
public string Name { get; protected set; }
public IReadOnlyDictionary<string, string> Claims { get; protected set; }
public bool IsAdmin { get; }
}
Now we can create an instance of User that contains safe defaults, like an empty claims dictionary so the IsAdmin helper (which presumably looks into Claims, will return false). One way to define the class is to use inheritance, like so:
public class NullUser : User
{
public NullUser() : base(string.Empty, EmptyClaims)
{
}
private static readonly IReadOnlyDictionary<string, string> EmptyClaims = new Dictionary<string, string>();
}
Now we can write a method that always return a safe value.
private static readonly NullUser nullUser = new NullUser();
User GetCurrentUser()
{
// if user not found :
return nullUser;
}
If we start thinking about alternatives to null today, we'll be better set to handle the future.
There is a new feature coming with version 8 of the C# compiler that will help us avoid nulls and all the problems they bring. The feature is non-nullable reference types. I expect most teams to aggressively adopt C# 8 after the release later this year, at least for new code. You can find many examples of the new feature in Microsoft docs and blogs, but the idea is to tell the C# compiler if a null value is allowed, or not, in each variable. The C# compiler can aggressively check code to make sure non-nullable reference types do not receive a null value. Using these types should give us simpler code, and force us to think before adding a return null.
Ten years ago, Tony Hoare apologized for inventing null, calling the null reference a billion dollar mistake. Let's see if we can avoid using his mistake!
When I started developing with ASP.NET many years ago, we used two tools on a regular basis. We used Visual Studio to write code for applications, and Internet Information Services (IIS) to host the applications.
IIS runs as a privileged service in Windows, meaning IIS has access to resources, APIs, and data structures on a machine that a normal user couldn’t read or write. The extra privilege afforded to IIS works well when you want to run an application in production and execute as fast as possible, but is a problem when you want to develop, test, or debug an application. Debugging, for example, requires an intimate relationship between two processes where the debugger controls the execution and the memory space of the debugee. Attaching a debugger to a privileged process like IIS isn’t something ordinary users should be able to do.
Debugging a privileged process requires … privileges, which is why Visual Studio requires us to run as an Administrator if an ASP.NET project uses IIS for hosting. Running a development tool as the machine administrator violates the principle of least privilege, which is a principle we should all value in these dark days of phishing attacks, data breaches, and Snapchat.
Microsoft released IIS Express in 2010 to help us develop, test, and debug applications without elevating into the administrator role. The express version of IIS has most of the key features that IIS includes for hosting and running web applications. But, instead of running as a privileged service, IIS express runs as a normal process using the same identity as the developer.
A few older projects I've been in lately still require IIS, which requires running as an Administrator. This is certainly not a situation you want for new applications, and it should be part of a migration plan when working with older applications. In Visual Studio you can right-click on an ASP.NET project and go to the web properties to configure a project for using IIS Express.
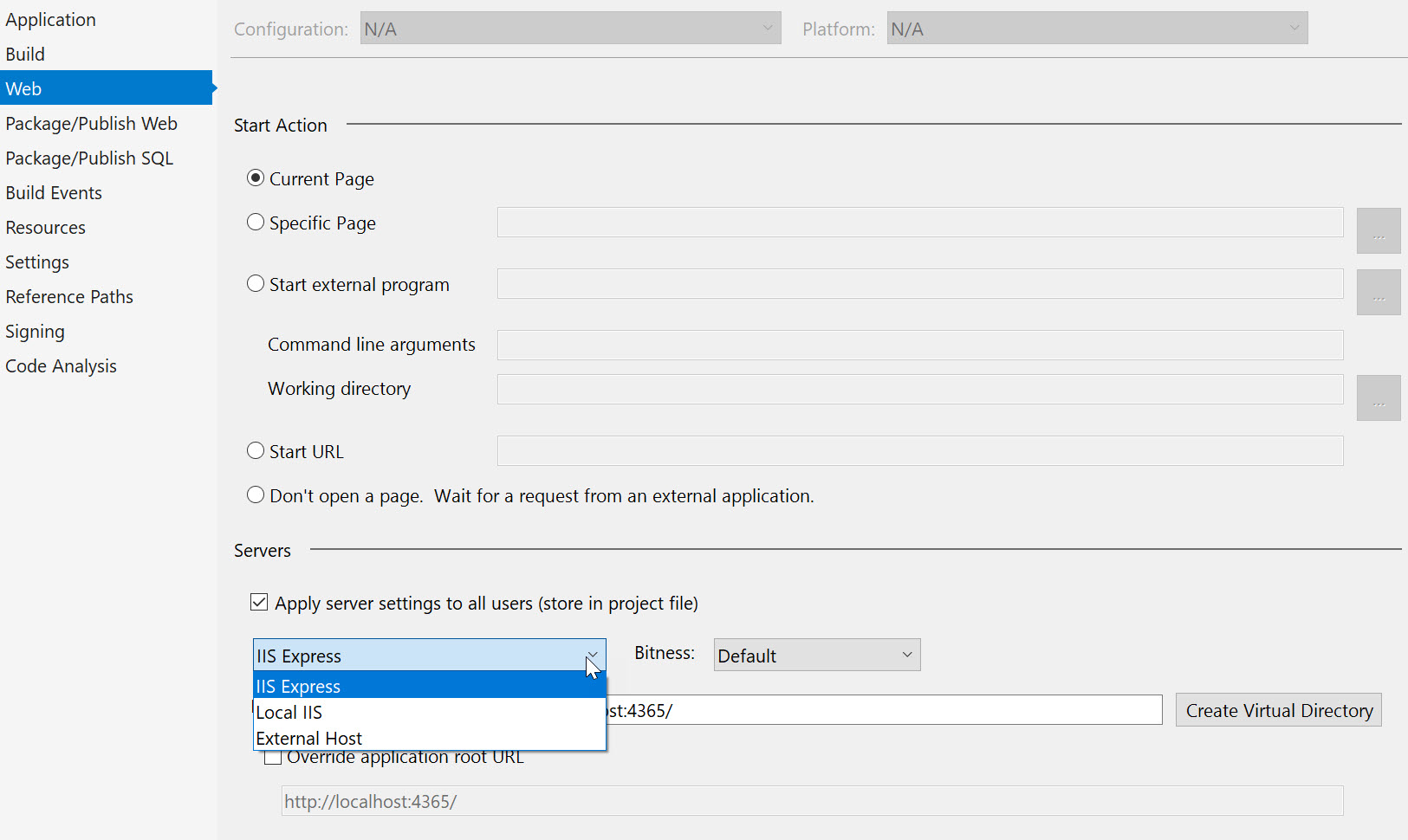
Using IIS Express for developing with ASP.NET will help us obey the principle of least privilege but might present some other difficulties. IIS Express works best with monolithic applications. We’ll need some extra setup for systems composed of multiple services, processes, and applications. Since Express doesn’t run as a service, Visual Studio has to launch your applications on demand. If you want to have multiple applications and services running concurrently without launching Visual Studio and opening a project for each component, than the following tips might help.
You can still configure IIS with websites pointing to all the components in a system. You’ll only be able to debug the component running in Express with Visual Studio, but at least the other services are alive and responding.
You can use the command line to run Express and launch as many applications and services as you need (see https://docs.microsoft.com/en-us/iis/extensions/using-iis-express/running-iis-express-from-the-command-line).
For more complicated scenarios, look into using containers and container orchestration.
So while there might be some extra work involved, not running as an administrator gives you a better security profile, and helps to obey the principle of least privilege.
Over the last few months I've put some work into explaining Azure App Services.
Demystifying Azure App Services is a look behind the abstraction of Azure App Services.
Demystifying Azure App Services Plans gets into the details of what makes an App Service Plan.
Demystifying Azure App Services – Diagnostics and Telemetry looks at some of the gems in App Services smart and opinionated diagnostics.
Here's a recording of my App Service talk at NDC Oslo.
I hope you enjoy the material!

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#