
 The hosting model for ASP.NET Core is dramatically different from previous versions of ASP.NET. This is also one area where I’ve seen a fair amount of misunderstanding.
The hosting model for ASP.NET Core is dramatically different from previous versions of ASP.NET. This is also one area where I’ve seen a fair amount of misunderstanding.
ASP.NET Core is a set of libraries you can install into a project using the NuGet package manager. One of the packages you might install for HTTP message processing is a package named Microsoft.AspNetCore.Server.Kestrel. The word server is in the name because this new version of ASP.NET includes its own web servers, and the featured server has the name Kestrel.
In the animal kingdom, a Kestrel is a bird of prey in the falcon family, but in the world of ASP.NET, Kestrel is a cross-platform web server. Kestrel builds on top of libuv, a cross-platform library for asynchronous I/O. libuv gives Kestrel a consistent streaming API to use across Windows and Linux. You also have the option of plugging in a server based on the Windows HTTP Server API (Web Listener), or writing your own IServer implementation. Without good reason, you’ll want to use Kestrel by default.
You can configure the server for your application in the entry point of the application. There is no Application_Start event in this new version of ASP.NET, nor is there any default XML configuration files. Instead, the start of the application is a static Main method, and configuration lives in the code.
public class Program
{
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup<Startup>()
.Build();
host.Run();
}
}
If you are looking at the above Program class with a static Main method and thinking the code looks like what you would see in a .NET console mode application, then you are thinking correctly. Compiling an ASP.NET project still produces a .dll file, but with .NET Core we launch the web server from the command line with the dotnet command line interface. The dotnet host will ultimately call into the Main method. In this way of working, .NET Core resembles environments like Java, Ruby, and Python.

If you are working on ASP.NET Core from Visual Studio, then you might never see the command line. Visual Studio continues to do a job it has always done, which is to hide some of the lower level details. With Visual Studio, you can set the application to run with Kestrel as a direct host, or to run the application in IIS Express (the default setting). In both cases, the dotnet host and Kestrel server are in play, even when using IIS Express. This brings us to the topic of running applications in production.
One you realize that ASP.NET includes a cross-platform host and web server, you might think you have all the pieces you need to push to production. There is some truth to this line of thought. Once you’ve invoked the Run method on the WebHost object in the above code, you have a running web server that will listen to HTTP requests and can work on everything from a 32 core Linux server to a Raspberry Pi. However, Microsoft strongly suggests using a hardened reverse proxy in front of your Kestrel server in production. The proxy could be IIS on Windows, or Apache or NGINX.

Why the reverse proxy? In short because technologies like IIS and Apache have been around for over 20 years and have seen all the evils the Internet can deliver to a network socket. Kestrel, on the other hand, is still a newborn babe. Also, reliable servers require additional infrastructure like careful process management to restart failed applications. Outside of ASP.NET, in the world of Java, Python, Ruby, and NodeJS web apps, you’ll see tools like Phusion Passenger and PM2 work in combination with the reverse proxy. These types of tools provide the watchdog monitoring, logging, balancing, and overall process management needed for a robust server. With ASP.NET Core on Windows you can use IIS to achieve the same goals. HTTP requests will still arrive at IIS first, and IIS can forward requests to the Kestrel application. You can have multiple applications deployed behind a single instance of IIS, and IIS will manage the application and provide logging, request filtering, URL rewrites, and many other useful features. In a way, this isn’t much different than what we’ve done in the past with ASP.NET, but once you dig behind the architectural diagrams, you’ll see the details are very different.
Deploying ASP.NET Core applications to IIS requires a web.config file. ASP.NET Core knows nothing about web.config files. The web.config file only exists to configure IIS in a reverse proxy role. A typical web.config file will look like the following.
<configuration>
<system.webServer>
<handlers>
<add name="aspNetCore" path="*" verb="*" modules="AspNetCoreModule" resourceType="Unspecified" />
</handlers>
<aspNetCore processPath="dotnet" arguments=".\TheWebApp.dll" stdoutLogEnabled="false"
stdoutLogFile=".\logs\stdout" forwardWindowsAuthToken="false" />
</system.webServer>
</configuration>
The web.config file instructs IIS to send requests for all paths and verbs to a new HTTP handler named aspNetCore. This ASP.NET Core Module for IIS is a piece of software you’ll need to install on an IIS server to run ASP.NET Core applications. The ASP.NET Core Module is available with the .NET Core SDK install, or with a special Windows Server Hosting .NET Core installer.
The second bit of the web.config file configures the ASP.NET Core module with instructions on how to start your application, which is to use the same dotnet command we saw earlier. Now, instead of our ASP.NET application running inside of a w3wp.exe IIS worker process, the application will execute inside of a dotnet.exe process.
With a better idea of how ASP.NET Core runs in production, let’s talk about benefits and risks.
One benefit to Kestrel is the ability to execute across different platforms. You can author an ASP.NET application on Windows using Visual Studio and IIS Express, but deploy the application on Linux with Apache in front. In all scenarios, the server is always Kestrel and your application code doesn’t need to change.
Another benefit to Kestrel is the incredible work Microsoft has put into making a blazing fast web server with managed code. Inside the readme file for the ASP.NET Benchmarks repository, you’ll currently find benchmarks showing ASP.NET Core serving five times the number of requests per second as ASP.NET 4.6 on the same hardware. 313,001 requests per second compared to 57, 843.

Of course, benchmark code and benchmark results don’t always reflect how a specific business application will behave. It’s like seeing an F1 racing car manufactured by Toyota on the television and then thinking you’ll find a car that goes 220 mph at the local Toyota dealer. What you will find at the dealer are cars that indirectly benefit from the millions of dollars that Toyota puts into researching new technologies for their F1 cars. The benefits trickle down.
I decided to try some comparative benchmarks of my own. I created three applications with ASP.NET WebForms, ASP.NET MVC 5, and ASP.NET MVC Core. Each application delivers 3kb of HTML to the client using the typical patterns you would find in business applications. For example, using a master page in WebForms and using a Layout page in MVC. For ASP.NET MVC Core, I ran tests against a naked Kestrel server as well as a Kestrel server proxied by IIS.

In my tests, the naked Kestrel server delivered 5 times the throughput of WebForms, and over twice the throughput of MVC 5. Once I moved the Core application behind IIS however, throughput dropped below the level of MVC 5. I know these results might surprise many people who believe that ASP.NET Core is inherently faster and lighter than its predecessors. However, ASP.NET Core’s predecessors were deeply integrated into IIS and could execute inside the same worker process where sockets were open. The current recommended setup adds an additional hop.
Another surprise – switching the ASP.NET Core application to run on the full .NET framework instead of .NET Core resulted in very little change in the throughput numbers. As developers, we want to believe .NET Core is also inherently faster and lighter than the full .NET framework, but for runtime performance in this specific application, the difference appears to be negligible.
I do think we can reasonably expect the performance of ASP.NET Core with IIS to improve in the future, so we’ll leave performance as a benefit.
The biggest risk I’ve seen in the new hosting model is the confusion that results in using IIS with ASP.NET Core. There are ASP.NET related settings in IIS that have no impact on a .NET Core application. These are settings like the pipeline mode (integrated or classic), and the setting to select a version of the .NET framework for a specific AppPool.

Developers and IT operations will need to understand the new deployment strategy and understand which IIS settings are significant and which settings to ignore. Both parties will also need to learn new troubleshooting techniques and diagnose a new set of common errors. 502.5 – “Failed to start process” is a terrifying new common error. One reason for this error is that the web.config file specifies incorrect arguments for the dotnet host.
Currently, I feel the hosting area is one of the bigger areas of risk in ASP.NET Core. However, I think we will be able to mitigate the risks over time through a combination of experience, education, experimentation, and improvements from Microsoft based on customer feedback. It is important for developers and IT operations to look at how to host an ASP.NET core application early and not treat deployment as a known procedure that can wait till the end of the project.
ASP.NET Core and the Enterprise Part 1: Frameworks
ASP.NET Core and the Enterprise Part 2: Hosting (current)
When larger companies with larger development teams ask me about ASP.NET Core, I generally frame the conversation in terms of risk and reward. Yes, there is a new architecture and yes, there are new features, but, when working on business applications with long lifecycles you want to look beyond the obvious topics for evangelism and measure the risks.
There are six areas to consider in evaluating ASP.NET Core and it’s impact on business and operations.
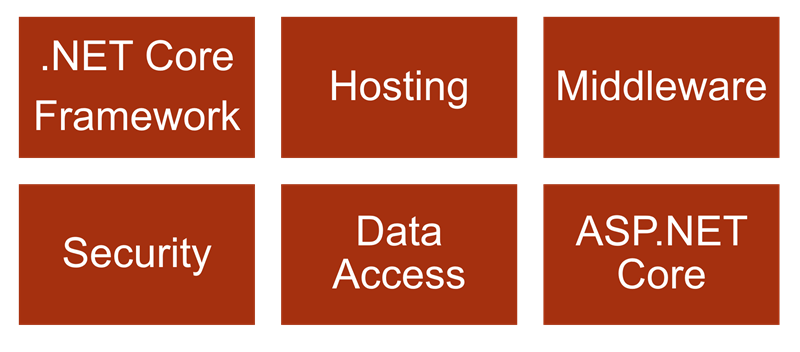
First is understanding ASP.NET Core’s relationship with the new .NET Core framework. That’s the topic for this post. In the future we’ll also be evaluating the new hosting model for ASP.NET Core, the HTTP processing pipeline, security features, the new data access landscape, and finally ASP.NET Core itself.
We now have two distinct flavors of the .NET framework to choose from. First there is the full .NET framework. The full .NET framework is the mature .NET framework that has been around since the beginning, is pre-installed with Windows, and includes application level frameworks like windows forms, web forms, WCF, and WPF. The most recent version at this time is 4.6.2.
We also have .NET Core, a new and modular version of .NET that runs on more than just the Windows operating system.
Where ASP.NET Core fits into the picture is that ASP.NET Core is an application framework that can run on either the full .NET framework or on .NET Core. Selecting a .NET framework flavor is one of your first decisions when making a move to ASP.NET Core. Do you want to run on the full framework, or .NET Core, or will you need to support both?
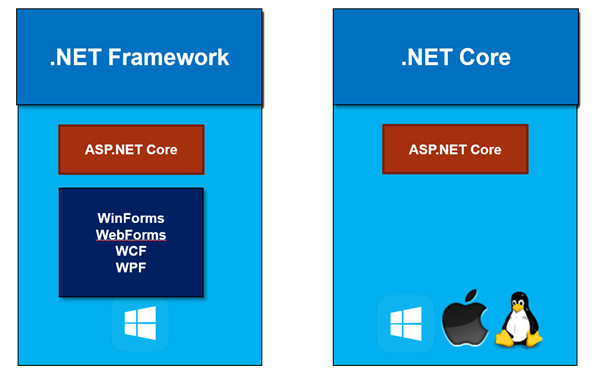
When you choose to run on the full .NET framework you are running on the framework you already know. Yes, ASP.NET Core will be a bit different from the ASP.NET frameworks of the past, but your underlying framework is the same. In order to understand why you might chose .NET Core instead of the full framework we need to dig into the risk and rewards of .NET Core.
.NET Core is a cross-platform framework, meaning.NET Core will run on Windows, on the Mac, and on various flavors of Linux. .NET Core also works in a Docker container for those who are using or thinking about using Docker software containers.
One must understand that ASP.NET Core does not require .NET Core as the underlying framework. But, if you do choose to use .NET Core as your underlying framework, you will be able to author and deploy ASP.NET applications and services on all of these various platforms. Linux is, of course, a big target for server-side applications. Most enterprises are heterogeneous and already have the IT expertise to run business applications on both Windows and Linux servers. There is also the opportunity to save money as Linux servers typically run a bit cheaper, particularly when using cloud based infrastructure. On Azure, for example, a single 4 core virtual machine running Linux is currently around $90 cheaper per month than its Windows counterpart.
What’s not immediately obvious when talking about a cross-platform .NET framework is how the necessary tooling also works across platforms. .NET Core has no hard dependency on Windows or Visual Studio. All of the low level tools you need to do work will run from the command line. There is an entire new world of text editors and IDEs available that we can now use to develop .NET applications, including Visual Studio code from Microsoft, Project Rider from Jet Brains, as well as text editors like Sublime and Atom.
I’ve worked on more than one project over the years where there is a front-end specialist who uses a Mac. The front-end developer hasn’t been able to install Visual Studio and work with an ASP.NET project the same way a Windows developer would work with the project. This type of scenario is considerably easier with .NET Core because a developer on Apple hardware can write, run, and debug ASP.NET code just as well as a developer on Windows.
.NET Core is also an open source project. On GitHub you can find not just the code for the framework itself, but also the code for the unit tests, and the documentation. You can view bugs in the GitHub issues list and see the current status of a bug. I’ve been telling people that one of the underappreciated advantages of Microsoft’s move towards open source is not in having the source code to a framework or library. We’ve always been able to get source code, even if we had to use a de-compiler. What I’ve found valuable are the unit tests, because they often given me better insight into how a particular feature works compared to using documentation or the source code itself. The unit tests can describe a feature from several different perspectives and also tell me what a piece of software is not designed to do.
In the enterprise, there is often a worry that open source projects do not have the same level of support as closed source commercial products. However, Microsoft has announced a support lifecycle of 3 years for each major and minor release of .NET Core. The .NET Core 1.0.0 release was June 27, 2016, meaning the end of support for 1.0.0 is in June of 2019, or even later if there is a Long Term Support (LTS) release in the future.

Something you’ll notice when looking at the source code on GitHub is how modular the new .NET Core has become. This is no longer a monolithic framework where you have everything or you have nothing at all. With .NET Core the fundamental pieces are smaller and integrated with the NuGet package management ecosystem. You can pull in just the pieces of .NET Core that you need to build an application.
.NET Core also supports an application deployment model known as a self-contained deployment. A self-contained deployment means you can put your asp.net core application into production with all of the .NET core assemblies the application needs to function, and these framework assemblies are all local. There is no global assembly cache, there is no framework installation required on the server. If you want a micro-services architecture with two dozen services deployed on one server, each ASP.NET Core service can deploy with it’s own version of the .NET Core framework and never need to worry about conflicting with the versions of other services or requiring the other services to upgrade. Everyone lives in perfect isolation. The downside here being that you’ll need to manage patches and updates to the framework for each deployment.
Are there other downsides?
Making a cross platform version of the .NET framework required some hard work and sacrifices. If the full .NET framework was a diet plan, you could have doughnuts for breakfast, a deep dish pizza for lunch, and a bacon cheeseburger with egg on top at dinner time. No human can really consume this many calories in a day, but the calories are there for you if you want to try and eat them all. .NET Core is more of a lite meal with all the essential vitamins included. But, depending on your appetite, you might not find enough here.

Where am I going with this analogy?
When I say that there were sacrifices made in creating .NET Core, I mean some technologies and features are missing, and some frameworks of the past will probably never appear in .NET Core.
There are generally three reasons for a feature of .NET to not appear in .NET Core. One reason is that there wasn’t enough time to port a feature to .NET core and the team is still working on expanding coverage. A second reason is that a feature might not make sense for a cross platform library and only makes sense on Windows. And finally, there are some technologies in .NET that have been around for 15+ years and are not going to move forward.
Unfortunately, many of us working in the enterprise space still use frameworks introduced in the original .NET framework of 2001. So what are the big pieces that are missing and what do you need to know?
For starters, there are entire frameworks that have not made the move to .NET Core. These are frameworks like WinForms, WebForms, WPF, Workflow, and WCF. From an ASP.NET perspective we don’t really care about desktop technologies like WPF, but there is a tremendous amount of enterprise software written using WebForms, and there are a tremendous number of services using WCF. I also know there is still software around using the predecessor to WCF, which was ASMX web services. Applications that rely on these frameworks might never move to .NET Core as they will require a re-design and a re-write. When you think about WCF in particular, a rewrite might not only impact your business but also your partner’s business.
I do want to point out that when it comes to WCF there is no server side WCF replacement. But, if you are writing a server-side application that consumes WCF services hosted in another service, there is an open source version of the WCF client libraries available. There is also some tooling (currently in beta) for Visual Studio for adding a service reference to a .NET Core application.

There are also features that are not in .NET Core, at least not currently. Some of these may appear in the future, but these are features like the once hugely popular DataSet class. There is also no support for working with XML schemas or XSLT in .NET core. There are no distributed transactions (perhaps a good thing), no ability to communicate with LDAP or ActiveDirectory, and no class for interacting with an SMTP server. Some of these features, like LDAP and SMTP can be replaced with HTTP based cloud services or third party providers, but this will still require some work in a legacy code base.
Some features exist in .NET Core, but with small changes in the API. Examples include the reflection API (changed for performance) and the encryption API (for better cross-platform support).
When moving to .NET core you also need your third party dependencies to support .NET core. Many popular libraries like StructureMap, Automapper, Mediatr, and JSON.net all have working versions for .NET core. MongoDB, as of this writing, just released a .NET Core driver. Oracle support for the Entity Framework, however, still has plans for .NET Core. If you rely on third party libraries, you’ll need those libraries to port to .NET Core, or find an alternative, or re-write your application to remove the dependency.
One tool you might find useful in analyzing your applications is the .NET Portability Analyzer. You can run the analyzer as a Visual Studio extension, or from the command line. With the analyzer you can select a target platform, like .NET Core, or ASP.NET Core, or a specific version of the full .NET framework, and the tool can tell you what problems you’ll face.
To summarize this part of the conversation, I think we are still a few years away from seeing .NET Core play a large role in the enterprise. We have a tremendous amount of legacy code that relies on WebForms and WCF services. There might not be enough of a return on investment to re-write or port these applications, at least not at this early stage in 2016.
However, it is clear that Microsoft’s future direction is in the Core space. Yes, the last update to the full .NET framework did include improvements for ASP.NET and WebForms, but clearly the future innovation and hard work will be in the new core frameworks like .NET core, ASP.NET Core, Entity Framework core, and whatever other cores come along in the future.
I do believe that now is a good time to start some planning and start prototyping. If you have requirements for new server-side applications, I’d push to try using .NET Core first, and fall back to the full framework if there is too much pain. Running ASP.NET Core on the full .NET framework will solve many problems with missing features and third party dependencies. Yes, running ASP.NET Core on the full framework does feel like a temporary solution to use in transition, but it is a step in the right direction, even if the solution feels messy. In the enterprise, we always have to deal with messy. Plus, the expertise an enterprise can gain in these early days will pay dividends in five years.
ASP.NET Core and the Enterprise Part 1: Frameworks (current)
I’ve re-recorded my ASP.NET Core Fundamentals course for Pluralsight using the released bits of ASP.NET Core 1.0. I hope you enjoy the videos!
In the future I’d like to record videos showing my opinionated approach to using ASP.NET on larger projects. Let Pluralsight know if that’s the type of content you’d like to see!

This post is one in a series of posts where I describe common problems developers face using ES2015 features of JavaScript. In this post we look at modules.
The first pitfall developers hit when using modules is making assumptions about the syntax. I fell into this trap myself.
import {Person, Animal} from "./lib"
Curly braces in JavaScript appear everywhere. We use them to define block statements, object literals, and more recently, use them for destructuring. Once I learned about destructuring, I looked at my next import statement and wrongly assumed JavaScript was destructuring a node-like module object into new variables.
That’s all wrong!
Import statements create bindings with behaviors that transcend mere variable declarations.
Consider a module with the following export.
export let counter = 0;
And now a module that wants to consume the export.
import {counter} from "./lib/exporter";
counter = 2;
The code trying to set the counter is in error because import bindings are immutable.
What sort of error will you see?
The specification calls for a TypeError, however:
- we currently don’t have a runtime environment that uses ES modules natively because the module loading spec is still a work in progress, and
- we rely on transpilers to transform ES 2015 imports and exports into de-facto standards like CommonJS where the rules are relaxed
For those reasons, the error we will see (or not see) depends on the tools we use. For example, the TypeScript compiler will give an error on any assignment to counter – “Invalid left-hand side of assignment expression”. Babel will give us a similar build-time error. As an aside, this is the type of scenario that worries me. Features like import bindings, variable scopes, const, and others might work differently when we transpile for newer runtimes in the future and use these features natively. I don’t foresee catastrophic problems, but there will be some headaches along the way.
The behavior of bindings also surprises some developers, particularly when importing state from another module. Let’s add some additional exports to the exporting module.
export let counter = 0;
export let creature = {
name: "Oscar"
};
export function increment() {
counter += 1;
return counter;
}
export function inspect() {
return creature.name;
}
export function reset() {
creature = { name: "Oscar" };
}
Although we can’t import and then mutate the value of the counter binding, we can call a piece of code in the exporting module that can change the value of the counter.
import {counter, increment} from "./lib/exporter";
describe("binding behavior", () => {
it("is live", () => {
expect(counter).toBe(0);
increment();
expect(counter).toBe(1);
});
});
Notice the change to counter is visible inside the importing module. The same behavior holds for objects, too.
import {creature, inspect, reset} from "./lib/exporter";
describe("binding behavior", () => {
it("is live", () => {
expect(creature.name).toBe("Oscar");
// this is legal - not trying to change the binding
creature.name = "Scott";
// everyone sees the change, even the exporting module
expect(inspect()).toBe("Scott");
// but only the exporter can change the binding value
reset();
expect(creature.name).toBe("Oscar");
})
});
For developers, it’s important to understand that modules are singletons. Any module importing counter and creature will see the same values.
Node developers accustomed to the flexibility of ConmmonJS can be disappointed by the inflexible, concrete nature of ES 2015 modules. The ES specification gives tools and runtimes the ability to statically analyze module code to discover imports and exports. Static analysis is good for early error detection, bundlers, optimizers, and tools in general, but not so good for anyone who wants to dynamically load modules. Dynamic loading is not out of the question, however. Dynamic loading will be something you can do with the module loading API at runtime (System.import, for example), but not with the ES syntax itself.
Which isn’t too say there is no flexibility in ES modules. RxJS 5 has an interesting design. The following import statement brings in large swaths of the library so you do not need to explicitly add individual operators.
import {Observable} from "rxjs";
If you want to build a smaller application bundle, you can import Observable from a different location and add just the operators you need.
import {Observable} from "rxjs/Observable";
import "rxjs/add/operator/map";
Finally, another area of confusion exists when working with libraries like React that provide both named and default exports. To grab a default export, the code doesn’t use curly braces.
import React, {Component} from "react";
I’ve seen a few developers try to use the braceless syntax to grab named exports, but without braces you can only grab the default export.
The Troubles with JavaScript Classes
The Troubles with JavaScript Arrow Functions
There is an instant in time when an ASP.NET application is fully alive and configured but it still held in check and waiting for a signal from the starter’s gun. This moment exists between the lines of code in Program.cs, and it is here where I’ve found a nice place to automatically run database migrations and seed a database based on command line arguments to the program.
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup<Startup>()
.Build();
ProcessDbCommands(args, host);
host.Run();
}
ProcessDBCommands is the method I use in the above code, and the logic here can be as simple or as complicated as you need. In my case, I’m just going to look for keywords in the arguments to drop, migrate, and seed the database. For example, running “dotnet run dropdb migratedb seeddb” will execute all three options against the configured database.
private static void ProcessDbCommands(string[] args, IWebHost host)
{
var services = (IServiceScopeFactory)host.Services.GetService(typeof(IServiceScopeFactory));
using (var scope = services.CreateScope())
{
if (args.Contains("dropdb"))
{
Console.WriteLine("Dropping database");
var db = GetLeagueDb(scope);
db.Database.EnsureDeleted();
}
if (args.Contains("migratedb"))
{
Console.WriteLine("Migrating database");
var db = GetLeagueDb(scope);
db.Database.Migrate();
}
if (args.Contains("seeddb"))
{
Console.WriteLine("Seeding database");
var db = GetLeagueDb(scope);
db.Seed();
}
}
}
private static LeagueDb GetLeagueDb(IServiceScope services)
{
var db = services.ServiceProvider.GetRequiredService<LeagueDb>();
return db;
}
A couple notes on the above code.
IWebHost gives us access to a fully configured environment, so connection strings and services are available just as they are inside the rest of the post-startup application code.
The db.Database.EnsureDeleted and db.Database.Migrate methods are built-in APIs for EF Core. The Seed method, on the other hand, is a custom extension method.
Over the summer I gave a talk titled “The New Dragons of JavaScript”. The idea was to provide, like the cartographers of the Old World, a map of where the dragons and sea serpents live in the new JavaScript feature landscape. These mythological beasts have a tendency to introduce confusion or pain in software development.
One area I covered were the quirks you might run into with JavaScript classes. Some introductions explain how classes work by describing the de-sugaring a transpiler applies to transform a class into the classical constructor function and prototype manipulation we’ve used in JavaScript for many years.
class Employee {
constructor(name) {
this._name = name;
}
doWork() {
return `${this._name} is working`;
}
}
// above code becomes ...
let Employee = function(name) {
this._name = name;
};
Employee.prototype = {
doWork: function() {
return `${this._name} is working`;
}
}
Constructor functions and prototypes are a useful mental model to have at times, but also leads to trouble because classes aren’t exactly like using constructor functions. For example, functions in JavaScript will hoist, but classes do not. If you ever want to push the definition of a small utility class to the bottom of a file and try to use the class in the code at the top of the file, you’ll be setting yourself up for an error.
// this code works
const e = new Employee();
function Employee() {
}
// this code produces a ReferenceError
const e = new Employee();
class Employee {
}
Technically, classes (and variables declared with let and const) do hoist themselves, but they hoist themselves into an area the early specs referred to as the “temporal dead zone”. Accessing a symbol in its TDZ creates a RefernceError. As an aside, “Temporal dead zone” is, I think, one of the greatest computer science terms ever conceived and should also be the title of a Hollywood film starring Mark Wahlberg.
Another difference between creating an object using a class and creating an object with a constructor function is in reflective code. It’s easy to discover the methods of an object instantiated with a constructor function using a for in loop.
const Human = function () { }
Human.prototype.doWork = function () { };
let names = [];
for (const p in new Human()) {
names.push(p);
}
// ["doWork"]
The same code won’t work when using a class definition.
class Horse {
constructor() {}
doWork() { }
}
names = [];
for (const p in new Horse()) {
names.push(p);
}
// []
However, it is possible to get to the methods of a class using some Object APIs.
names = [];
const prototype = Object.getPrototypeOf(new Horse());
for(const name of Object.getOwnPropertyNames(prototype)) {
names.push(name);
}
// ["constructor", "doWork"]
Coming soon – The Troubles with Modules.
Previously in this series – The Trouble with JavaScript Arrow Functions
I’ve been kicking around the idea of combining [HttpPost] and [ValidateAntiForgeryToken] in an application using authentication cookies. Both attributes typically appear together to prevent cross-site request forgeries in MVC applications using cookie based authentication. The result looks like the following.
[HttpPostWithValidAntiForgeryToken]
public IActionResult Edit(Input model)
{
// ...
}
And the attribute definition is as follows.
public class HttpPostWithValidAntiForgeryToken
: Attribute, IActionHttpMethodProvider, IFilterFactory
{
private readonly HttpPostAttribute _postAttribute;
private readonly ValidateAntiForgeryTokenAttribute _antiForgeryAttribute;
public HttpPostWithValidAntiForgeryToken()
{
_postAttribute = new HttpPostAttribute();
_antiForgeryAttribute = new ValidateAntiForgeryTokenAttribute();
}
public IEnumerable<string> HttpMethods => _postAttribute.HttpMethods;
public IFilterMetadata CreateInstance(IServiceProvider serviceProvider)
{
return _antiForgeryAttribute.CreateInstance(serviceProvider);
}
public bool IsReusable => _antiForgeryAttribute.IsReusable;
}
With the new attribute, a plain [HttpPost] should never appear in the application, and a unit test using reflection could enforce the rule.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#