
My latest Pluralsight course is “Building Your First Salesforce Application”.
Learn how to work with Salesforce.com by creating custom applications. Start by signing up for a developer account on Salesforce.com, and finish with a full application including reports and dashboards that work on both desktops and mobile devices.
Salesforce is a new territory for me, and when the course was announced the question poured in. Are you moving to the Salesforce platform?
The short answer is no.
The longer answer is that I hear Salesforce in conversations more often. Companies and developers need to either build software on the Salesforce platform or use Salesforce APIs. There was a time when I thought of Salesforce as a customer relationship solution, but in these conversations I also started to hear Salesforce described as a database, as a cloud provider, and as an identity provider. I wanted to find out for myself what features and capabilities Salesforce could offer. I spent some time with a developer account on Salesforce, and when Pluralsight said they needed a beginner course on the topic, I decided to make this course.
I hope you enjoy watching and learning!
I've seen parameter validation code inside controller actions on an HTTP GET request. However, the model binder in ASP.NET Core will populate the ModelState data structure with information about all input parameters on any type of request.
In other words, model binding isn't just for POST requests with form values or JSON.
Take the following class, for example.
public class SearchParameters
{
[Required]
[Range(minimum:1, maximum:int.MaxValue)]
public int? Page { get; set; }
[Required]
[Range(minimum:10, maximum:100)]
public int? PageSize { get; set; }
[Required]
public string Term { get; set; }
}
We'll use the class in the following controller.
[Route("api/[controller]")]
public class SearchController : Controller
{
[HttpGet]
public IActionResult Get(SearchParameters parameters)
{
if (!ModelState.IsValid)
{
return BadRequest(ModelState);
}
var model = // build the model ...
return new OkObjectResult(model);
}
}
Let's say a client sends a GET request to /api/search?pageSize=5000. We don't need to write validation code for the input in the action, all we need to do is check model state. For a request to /api/search?pageSize=5000, the above action code will return a 400 (bad request) error.
{
"Page":["The Page field is required."],
"PageSize":["The field PageSize must be between 10 and 100."],
"Term":["The Term field is required."]
}
For the Required validation to activate for Page and PageSize, we need to make these int type properties nullable. Otherwise, the runtime assigns a default value 0 and the Range validation fails, which might be confusing to clients.
Give your input model a default constructor to provide default values and you won't need nullable properties or the Required attributes. Of course, this approach only works if you can provide sensible default values for the inputs.
public class SearchParameters
{
public SearchParameters()
{
Page = 1;
PageSize = 10;
Term = String.Empty;
}
[Range(minimum:1, maximum:int.MaxValue)]
public int? Page { get; set; }
[Range(minimum:10, maximum:100)]
public int? PageSize { get; set; }
public string Term { get; set; }
}
I’ve decided to write down some of the steps I just went through in showing someone how to create and debug an ASP.NET Core controller. The controller is for an API that needs to accept a few pieces of data, including one piece of data as a byte array. The question asked specifically was how to format data for the incoming byte array.
Instead of only showing the final solution, which you can find if you read various pieces of documentation, I want to show the evolution of the code and a thought process to use when trying to figure out the solution. While the details of this post are specific to sending byte arrays to an API, I think the general process is one to follow when trying to figure what works for an API, and what doesn’t work.
To start, collect all the information you want to receive into a single class. The class will represent the input model for the API endpoint.
public class CreateDocumentModel
{
public byte[] Document { get; set; }
public string Name { get; set; }
public DateTime CreationDate { get; set; }
}
Before we use the model as an input to an API, we’ll use the model as an output. Getting output from an API is usually easy. Sending input to an API can be a little bit trickier, because we need to know how to format the data appropriately and fight through some generic error messages. With that in mind, we’ll create a simple controller action to respond to a GET request and send back some mock data.
[HttpGet]
public IActionResult Get()
{
var model = new CreateDocumentModel()
{
Document = new byte[] { 0x03, 0x10, 0xFF, 0xFF },
Name = "Test",
CreationDate = new DateTime(2017, 12, 27)
};
return new ObjectResult(model);
}
Now we can use any tool to see what our data looks like in a response. The following image is from Postman.

What we see in the response is a string of characters for the “byte array” named document. This is one of those situations where having a few years of experience can help. To someone new, the characters look random. To someone who has worked with this type of data before, the trailing “=” on the string is a clue that the byte array was base64 encoded into the response. I’d like to say this part is easy, but there is no substitute for experience. For beginners, one also has to see how C# properties in PascalCase map to JSON properties in camelCase, which is another non-obvious hurdle to formatting the input correctly.
Once you’ve figured out to use base64 encoding, it’s time to try to send this data back into the API. Before we add any logic, we’ll create a simple echo endpoint we can experiment with.
[HttpPost]
public IActionResult CreateDocument([FromBody] CreateDocumentModel model)
{
return new ObjectResult(model);
}
With the endpoint in place, we can use Postman to send data to the API and inspect the response. We’ll make sure to set a Content-Type header to application/json, and then fire off a POST request by copying data from the previous response.
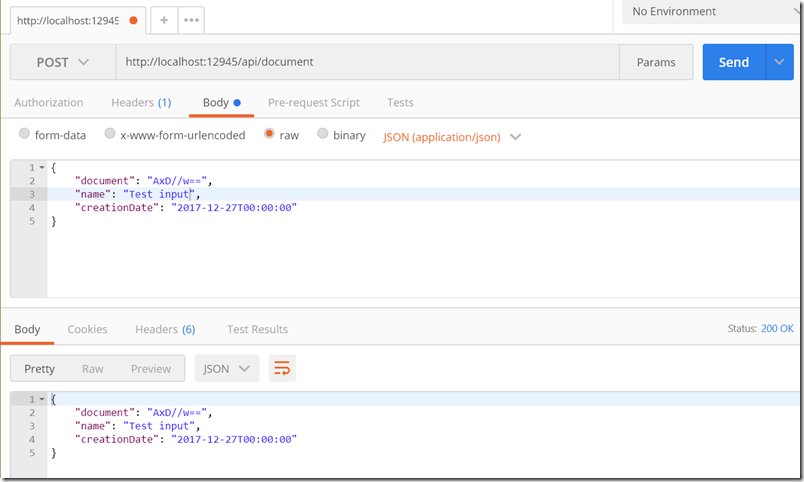
Voilà!
The model the API returns looks just like the model we sent to the API. Being able to roundtrip the model is a good sign, but we are only halfway through the journey. We now have a piece of code we can experiment with interactively to understand how the code will behave in different circumstances. We want a deeper understanding of how the code behaves because our clients might not always send the model we expect, and we want to know what can go wrong before the wrong things happen.
Here are some questions to ask.
Q: Is a base64 encoded string the only format we can use for the byte array?
A: No. The ASP.NET Core model binder for byte[] also understands how to process a JSON array.
{
"document": [1, 2, 3, 254],
"name": "Test input",
"creationDate": "2017-12-27T00:00:00"
}
Q: What happens if the document property is missing in the POST request?
A: The Document property on the input model will be null.
Q: What happens if the base64 encoding is corrupt, or when using an array, a value is outside the range of a byte?
A: The model input parameter itself will be null
I’m sure you can think of other interesting questions.
There are two points I’m making in this post:
1. When trying to figure out how to get some code to work, take small steps that are easy to verify.
2. Once the code is working, it is often worthwhile to spend a little more time to understand why the code works and how the code will behave when the inputs aren’t what you expect.
In a previous post we looked at using Azure AD groups for authorization. I mentioned in that post how you need to be careful when pulling group membership claims from Azure AD. In this post we’ll look at the default processing of claims in ASP.NET Core and see how to avoid the overheard of carrying around too many group claims.
The first issue I want to address in this post is the change in claims processing with ASP.NET Core 2.
Dominick Baier has a blog post about missing claims in ASP.NET Core. This is a good post to read if you are using the OIDC services and middleware. The post covers a couple different issues, but I want to call out the “missing claims” issue specifically.
The OIDC options for ASP.NET Core include a property named ClaimActions. Each object in this property’s collection can manipulate claims from the OIDC provider. By manipulate, I mean that all the claim actions installed by default will remove specific claims. For example, there is an action to delete the ipaddr claim, if present. Dom’s post includes the full list.
I think ASP.NET Core is removing claims to reduce cookie bloat. In my experiments, the dozen or so claims dropped by the default settings will reduce the size of the authentication cookies by 1,500 bytes, or just over 30%. Many of the claims, like IP address, don’t have any ongoing value to most applications, so there is no need to store the value in a cookie and pass the value around in every request.
If you want the deleted claims to stick around, there is a hard way and a straightforward way to achieve the goal.
I’ve seen at least two software projects with the same 20 to 25 lines of code inside. The code originates from a Stack Overflow answer to solve the missing claims issue and explicitly parses all the claims from the OIDC provider.
If you want all the claims, you don’t need 25 lines of code. You just need a single line of code.
services.AddAuthentication()
.AddOpenIdConnect(options =>
{
// this one:
options.ClaimActions.Clear();
});
However, make sure you really want all the claims saved in the auth cookie. In the case of AD group membership, the application might only need to know about 1 or 2 groups while the user might be a member of 10 groups. Let’s look at approaches to removing the unused group claims.
My first thought was to use the collection of ClaimActions on the OIDC options to remove group claims. The collection holds ClaimAction objects, where ClaimAction is an abstract base class in the ASP.NET OAuth libraries. None of the built-in concrete types do exactly what I’m looking for, so here is a new ClaimAction derived class to remove unused groups.
public class FilterGroupClaims : ClaimAction
{
private string[] _ids;
public FilterGroupClaims(params string[] groupIdsToKeep) : base("groups", null)
{
_ids = groupIdsToKeep;
}
public override void Run(JObject userData, ClaimsIdentity identity, string issuer)
{
var unused = identity.FindAll(GroupsToRemove).ToList();
unused.ForEach(c => identity.TryRemoveClaim(c));
}
private bool GroupsToRemove(Claim claim)
{
return claim.Type == "groups" && !_ids.Contains(claim.Value);
}
}
Now we Just need to add a new instance of this class to the ClaimActions, and pass in a list of groups we want to use.
options.ClaimActions.Add(new FilterGroupClaims(
"c5038c6f-c5ac-44d5-93f5-04ec697d62dc",
"7553192e-1223-0109-0310-e87fd3402cb7"
));
ClaimAction feels like an odd abstraction, however. It makes no sense for the base class constructor to need both a claim type and claim value type when these parameters go unused in the derived class logic. A ClaimAction is also specific to the OIDC handler in Core. Let’s try this again with a more generic claims transformation in .NET Core.
Services implementing IClaimsTransformation in ASP.NET Core are useful in a number of different scenarios. You can add new claims to a principal, map existing claims, or delete claims. For removing group claims, we first need an implementation of IClaimsTransformation.
public class FilterGroupClaimsTransformation : IClaimsTransformation
{
private string[] _groupObjectIds;
public FilterGroupClaimsTransformation(params string[] groupObjectIds)
{
// note: since the container resolves this service, we could
// inject a data access class to fetch IDs from a database,
// or IConfiguration, IOptions, etc.
_groupObjectIds = groupObjectIds;
}
public Task<ClaimsPrincipal> TransformAsync(ClaimsPrincipal principal)
{
var identity = principal.Identity as ClaimsIdentity;
if (identity != null)
{
var unused = identity.FindAll(GroupsToRemove).ToList();
unused.ForEach(c => identity.TryRemoveClaim(c));
}
return Task.FromResult(principal);
}
private bool GroupsToRemove(Claim claim)
{
return claim.Type == "groups" &&
!_groupObjectIds.Contains(claim.Value);
}
}
Register the transformer during ConfigureServices in Startup, and the unnecessary group claims disappear.
Group claims are not difficult to use with Azure Active Directory, but you do need to take care in directories where users are members of many groups. Instead of fetching the group claims from Azure AD during authentication like we've done in the previous post, one could change the claims transformer to fetch a user’s groups using the Graph API and adding only claims for groups the application needs.
 Authenticating users in ASP.NET Core using OpenID Connect and Azure Active Directory is straightforward. The tools can even scaffold an application to support this scenario.
Authenticating users in ASP.NET Core using OpenID Connect and Azure Active Directory is straightforward. The tools can even scaffold an application to support this scenario.
In this post I want to go one step further and define authorization rules based on a user’s group membership in Azure AD.
While the authentication picture is clear, authorization can be blurry. Authorization is where specific business rules meet software, and authorization requirements can vary from application to application even in the same organization. Not only will different applications need different types of authorization rules, but the data sources needed to feed data into those rules can vary, too.
Over the years, however, many applications have used group membership in Windows Active Directory (AD) as a source of information when making authorization decisions. Group membership in AD is reliable, and static. For example, a new employee in the sales department who is placed into the “Sales” group will probably remain in the sales group for the rest of their term.
Basing authorization rules on AD group membership was also easy in these apps. For ASP.NET developers building applications using IIS and Windows Authentication, checking a user’s group membership only required calling an IsInRole method.
Cloud native applications trade Windows Active Directory for Azure Active Directory and move away from Windows authentication protocols like NTLM and Kerberos to Internet friendly protocols like OpenID Connect. In this scenario, an organization typically synchronizes their Windows Active Directory into Azure AD with a tool like ADConnect. The synchronization allows users to have one identity that works inside the firewall for intranet resources, as well as outside the firewall with services like Office 365.
Windows Active Directory and Azure Active Directory are two different creatures, but both directories support the concepts of users, groups, and group membership. With synchronization in place, the group membership behind the firewall are the same as the group memberships in the cloud.
Imagine we have a group named “sales” in Azure AD. Imagine we want to build an application like the old days where only users in the sales group are authorized to use the application.
I’m going to assume you already know how to register an application with Azure AD. There is plenty of documentation on the topic.
Unlike the old days, group membership information does not magically appear in an application when using OIDC. You either need to use the Graph API to retrieve the groups for a specific user after authenticating, which we can look at in a future post if there is interest, or configure Azure AD to send back claims representing a user’s group membership. We’ll take the simple approach for now and configure Azure AD to send group claims. There is a limitation to this approach I’ll mention later.
Configuring Azure AD to send group claims requires a change in the application manifest. You can change the manifest using the AD graph API, or in the portal. In the portal, go to App registrations => All apps => select the app => click the manifest button on the top action bar.

The key is the “groupMembershipClaims” property you can see in the bottom screenshot. Set the value to “SecurityGroup” for Azure to return group information as claims. The app manifest includes a number of settings that you cannot reach through the UI of the portal, including appRoles. You'll probably want to define appRoles if you are building a multi-tenant app.
With the above manifest in place, you should see one or more claims named “groups” in the collection of claims Azure AD will return. An easy way to see the claims for a user is to place the following code into a Razor page or Razor view:
<table class="table">
@foreach (var claim in User.Claims)
{
<tr>
<td>@claim.Type</td>
<td>@claim.Value</td>
</tr>
}
</table>
With the default claim processing in ASP.NET Core (more on that in a future post), you’ll see something like the following for a user authenticated by Azure AD. 
For group membership you'll want to focus on the groups claims. The value of the claims for AD groups will be object IDs. You’ll need to know the object ID of the group or groups your application considers important. You can look in the Azure portal for the IDs or use the Azure CLI.
az>> ad group show --group Sales
{
"displayName": "Sales",
"mail": null,
"objectId": "c5038c6f-c5ac-44d5-93f5-04ec697d62dc",
"objectType": "Group",
"securityEnabled": true
}
With the ID in hand, you can now define an ASP.NET Core authorization policy. The authorization primitives in ASP.NET Core are claims and policies. Claims hold information about a user. Policies encapsulate simple logic to evaluate the current user against the current context and return true to authorize a user. For more sophisticated scenarios, one can also use authorization requirements and handlers in ASP.NET Core, but for group membership checks we can use the simpler policy approach.
Many people will place policy definitions inline in Startup.cs, but I prefer to keep some helper classes around and organized into a folder to make policy definitions easier to view. A helper class for a Sales policy could look like the following.
public static class SalesAuthorizationPolicy
{
public static string Name => "Sales";
public static void Build(AuthorizationPolicyBuilder builder) =>
builder.RequireClaim("groups", "c5038c6f-c5ac-44d5-93f5-04ec697d62dc");
}
In Startup.cs, we use the helper to register the policy.
public void ConfigureServices(IServiceCollection services)
{
services.AddAuthorization(options =>
{
options.AddPolicy(SalesAuthorizationPolicy.Name,
SalesAuthorizationPolicy.Build);
});
// ...
services.AddMvc();
}
There are many places where you can use a named policy in ASP.NET Core. There’s the Authorize attribute that’s been around forever.
[Authorize("Sales")]
public class HomeController : Controller
{
// ...
}
However, I strongly encourage developers to build custom attributes to be more expressive and hide string literals.
public class AuthorizeSales : AuthorizeAttribute
{
public AuthorizeSales() : base(SalesAuthorizationPolicy.Name)
{
}
}
// elsewhere in the code ...
[AuthorizeSales]
public class ReportController : Controller
{
}
For imperative code, inject IAuthorizationService anywhere and use the AuthorizeAsync method.
public async Task Tessalate(IAuthorizationService authorizationService)
{
var result = await authorizationService.AuthorizeAsync(
User, SalesAuthorizationPolicy.Name);
if (result.Succeeded)
{
// ...
}
}
You can also protect Razor Pages with a named policy.
services.AddMvc()
.AddRazorPagesOptions(o =>
{
o.Conventions.AuthorizeFolder("/Protected",
SalesAuthorizationPolicy.Name);
});
In larger organizations a user might be in hundreds of groups. If a user is in more than 250 groups, you’ll need to fall back to using the Graph API as Azure AD will not respond with the full list of user groups. Even if the user is only in 5 groups, your application may only care about 1 or 2 of the groups. In that case, you’ll want to cull the group claims to reduce the size of the authorization cookie that ASP.NET Core sends to the client browser. We’ll cover that topic and more in the next post.
PDF generation.
Yawn.
But, every enterprise application has an “export to PDF” feature.
There are obstacles to overcome when generating PDFs from Azure Web Apps and Functions. The first obstacle is the sandbox Azure uses to execute code. You can read about the sandbox in the “Azure Web App sandbox” documentation. This article explicitly calls out PDF generation as a potential problem. The sandbox prevents an app from using most of the kernel’s graphics API, which many PDF generators use either directly or indirectly.
The sandbox document also lists a few PDF generators known to work in the sandbox. I’m sure the list is not exhaustive, (a quick web search will also find solutions using Node), but one library listed indirectly is wkhtmltopdf (open source, LGPLv3). The wkhtmltopdf library is interesting because the library is a cross platform library. A solution built with .NET Core and wkhtmltopdf should work on Windows, Linux, or Mac.
For this experiment I used the Azure Functions 2.0 runtime, which is still in beta and has a few shortcomings. However, the ability to use precompiled projects and build on .NET Core are both appealing features for v2.
To work with the wkhtmltopdf library from .NET Core I used the DinkToPdf wrapper. This package hides all the P/Invoke messiness, and has friendly options to control margins, headers, page size, etc. All an app needs to do is feed a string of HTML to a Dink converter, and the converter will return a byte array of PDF bits.
Here’s an HTTP triggered function that takes a URL to convert and returns the bytes as application/pdf.
using DinkToPdf;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Extensions.Http;
using Microsoft.Azure.WebJobs.Host;
using System;
using System.Net.Http;
using System.Threading.Tasks;
using IPdfConverter = DinkToPdf.Contracts.IConverter;
namespace PdfConverterYawnSigh
{
public static class HtmlToPdf
{
[FunctionName("HtmlToPdf")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "post")]
ConvertPdfRequest request, TraceWriter log)
{
log.Info($"Converting {request.Url} to PDF");
var html = await FetchHtml(request.Url);
var pdfBytes = BuildPdf(html);
var response = BuildResponse(pdfBytes);
return response;
}
private static FileContentResult BuildResponse(byte[] pdfBytes)
{
return new FileContentResult(pdfBytes, "application/pdf");
}
private static byte[] BuildPdf(string html)
{
return pdfConverter.Convert(new HtmlToPdfDocument()
{
Objects =
{
new ObjectSettings
{
HtmlContent = html
}
}
});
}
private static async Task<string> FetchHtml(string url)
{
var response = await httpClient.GetAsync(url);
if (!response.IsSuccessStatusCode)
{
throw new InvalidOperationException($"FetchHtml failed {response.StatusCode} : {response.ReasonPhrase}");
}
return await response.Content.ReadAsStringAsync();
}
static HttpClient httpClient = new HttpClient();
static IPdfConverter pdfConverter = new SynchronizedConverter(new PdfTools());
}
}
Notice the converter class has the name SynchronizedConverter. The word synchronized is a clue that the converter is single threaded. Although the library can buffer conversion requests until a thread is free to process those requests, it would be safer to trigger the function with a message queue to avoid losing conversion requests in case of a restart.
You should also know that the function will not execute successfully in a consumption plan. You’ll need to use a Basic or higher app service plan in Azure.
To deploy the application you’ll need to include the wkhtmltopdf native binaries. You can build the binary you need from source, or download the binaries from various places, including the DinkToPdf repository. Function apps currently only support .NET Core on Windows in a 32-bit process, so use the 32-bit dll. I added the binary to my function app project and set the build action “Copy to Output Directory”. As we are about to see, the 32 bit address space is not a problem.
To see how the function performs, I created a single instance of the lowest standard app service plan (S1 – single CPU).
For requests pointing to 18KB of HTML, the function produces a PDF in under 3 seconds regularly, although 20 seconds isn’t abnormal either. Even the simplest functions on the v2 runtime have a high standard deviation for the average response time. Hopefully the base performance characteristics improve when v2 is out of beta.
Using a single threaded component like wkhtmltopdf in server-side code is generally a situation to avoid. To see what happens with concurrent users I ran some load tests for 5 minutes starting with 1 user. Every 30 seconds the test added another user up to a maximum of 10 concurrent users. The function consistently works well up to 5 concurrent requests, at which point the average response time is ~30 seconds. By the time the test reaches 7 concurrent users the function would consistently generate HTTP 502 errors for a subset of requests. Here are the results from one test run. The Y axis labels are for the average response time (in seconds).

Looking at metrics for the app service plan in Azure, you can see the CPU pegged at 100% for most of the test time. With no headroom left for other apps, you’d want to give this function a dedicated plan. 
I wouldn’t consider this solution viable for a system whose sole purpose is generating large number of PDF files all day, but for small workloads the function is workable. Much would depend on the amount of HTML in the conversion. In my experience the real headaches with PDFs come down to formatting. HTML to PDF conversions always look like they’ve been constructed by a drunken type-setter using a misaligned printing press, unless you control the HTML and craft the markup specifically for conversion.
 A recurring question in my C# workshops and videos sounds like: "How do you know when to define a new class?"
A recurring question in my C# workshops and videos sounds like: "How do you know when to define a new class?"
This question is a quintessential question for most object-oriented programming languages. The answer could require a 3-day workshop or a 300 page book. I'll try to distill some of my answers to the question into this blog post.
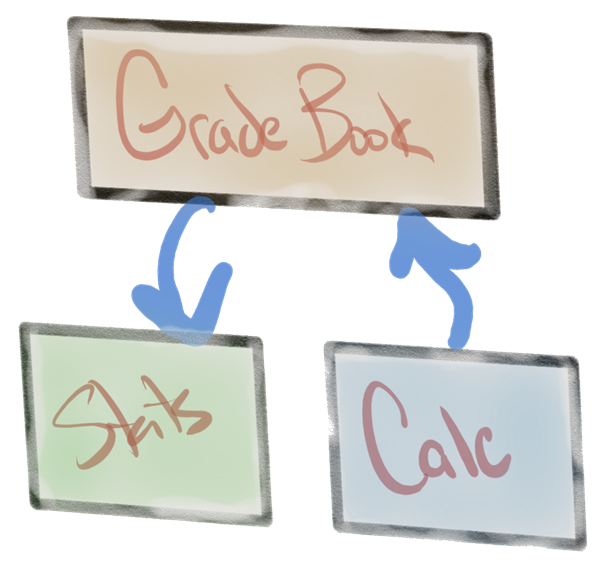
The question for this post regularly pops up in my grade book scenario. In the scenario I create a GradeBook class to track homework grades for a fictional class of students. The GradeBook starts simple and only offers the ability to add a new grade or fetch existing grades.
Eventually we reach the point where we need to compute some statistics on the grades stored inside the grade book. The statistics include the average grade, lowest grade, and highest grade. Later in the course we use the stats to compute a letter grade. It is the statistics part where I show how to create a new class to encapsulate the statistics.
Why?
Why not just add some properties to the existing GradeBook with the statistical values? Wouldn't it be better to have the statistics computed live when the program adds a new grade?
I'm always thrilled with these questions. Asking these questions means a student is progressing beyond the opening struggles of learning to program and is no longer just trying to make something work. They've grown comfortable with the tools and have fought off a few compiler errors to gain confidence. They've internalized some of the basic language syntax and are beginning to think about how to make thing work the right way.
It’s difficult to explain how the right way is never perfectly obvious. Most of us make software design decisions based on a combination of instincts, heuristics, and with our own biases, because there is no strict formula to follow. There can be more than one right way to solve every problem, and the right way for the same problem can change depending on the setting.
There are many different types of developers, applications, and business goals. All these different contexts influence how you write code.
Some developers write code for risk averse companies where application updates are a major event, and they make slow, deliberate decisions. Other developers write code for fast moving businesses, so having something delivered by next week is of utmost importance.
Some developers write code in the inner loop of a game engine, so the code must be as fast as possible. Other developers write code protecting private data, so the code must be as secure as possible.
Some developers pride themselves on craftsmanship. The quality of the code base is as important as the quality of the application itself. Other developers pride themselves on getting stuff done. Putting software in front of a user is the only measure of success. Exitus ācta probat.
Code that is good in one context might not be as good in one of the other contexts. Blog posts and tweets about design principles and best practices often neglect context. It is easy for an author to assume all the readers work in the same context as the author, and all the readers carry the same personal values about how to construct software. Trying to avoid assumptions about the reader’s context makes posts like this more difficult to write. But, like the Smashing Pumpkins song with the lyrics ‘paperback scrawl your hidden poems’, let me try, try, try.
But first, some background.
In a language like C# we have classes. Classes allow us to use an object-oriented approach to solving problems.
The antithesis of object-oriented programming is the transaction script. In a transaction script you write code inside a function from top to bottom. Object-oriented aristocrats will frown on transaction scripts as an anti-pattern because a transaction script is a procedural way of thinking. My code does step 1, step 2, ... step n. There is little to no encapsulation happening, even when using sub-functions to break up a large function.
Transaction scripts are not always bad, though. In some contexts, transaction scripts might be an ideal solution. Transaction scripts are easy to write. Transaction scripts are also generally easy to read because all the logic is in one place. There is no indirection and no need to jump around in different class files to see everything that is happening.
The problem with transaction scripts is in maintainability. Transaction scripts are typically inflexible. There is little chance of making a change to the behavior of a program without changing, and therefore potentially breaking, an existing piece of code. And, transaction scripts can be notoriously hard to unit tests, because the script typically mixes many different operations and responsibilities into a single pile of code.
The opposite of procedural programming with an object-oriented language is domain driven design. While transaction scripts offer a simple solution for simple problems, DDD is the complex approach for complex problems.
DDD solutions typically offer high levels of encapsulation. What might be 50 lines of code in a transaction script could be 5 classes with 10 lines of code each, although you’d never need DDD for 50 lines of code, so this is a silly comparison. The amount of effort put into modeling a complex domain means the code is more difficult to write. One can also argue the number of classes involved can also make the software more difficult to read, at least when looking at larger pieces of functionality. DDD is a winner for complex problems that will have a long-life span, because maintainability is easier over the long run. The high levels of encapsulation and isolation make it harder to make mistakes, and easier to avoid unintended consequences. Each class has clear responsibilities and decouple and orchestrate well with other classes.
At this point we know there are extremes in the different approaches you can use to apply C# to a programming problem. We also know that context is important when deciding on an approach. Now back to the question.
Why do I add a class to carry the data for the statistics of a gradebook?
One reason I added the class was to promote thinking about how to approach the problem in an object-oriented manner. To me, adding the class was the right approach. The feeling of rightness is based on my personal values formed across decades of programming with C# and languages like C#. This is not a feeling you’ll have when you first start programming. But, if you are introspective and eager to improve, you’ll develop your own heuristics on the rightness of an approach over time.
My sense of rightness is strongly influenced by the single responsibility principle. SRP says a class should have a single responsibility, or from another perspective, a class should have only one reason to change. Since the gradebook handles storing and retrieving individual grades, it doesn’t make sense for the gradebook to also manage statistics. Think about the documentation for a class. If you write a sentence saying you can use the class to ___ and ___ in a system, then it might be time to look at making two classes instead of one. You can forget all other design principles and get a long way towards better software construction just focusing on SRP, and this is regardless of being object-oriented, or functional, or some other paradigm.
I also think the approach I’m showing is an approach you can use in many different contexts. The statistics are a computed result. Having a dedicated class to represent the output of a decision or a calculation is good. If the statistics were instead properties on the grade book itself, I’d have to wonder if I need to call a method to initialize the properties, or if they are always up to date, or how I could pass the results around without exposing the entire grade book to other parts of the system. Having a dedicated result for the stats gives me a collection of values at a specific point in time. I can take the stats object and pass it to the UI for display, or record the stats for historical purposes, or pass the stats to a reporting object that will email the results to a student.
In my video version of the GradeBook course, my biggest regret is not going one step further and ripping the calculations out of the GradeBook. Calculating the statistics is a unique responsibility. The documentation would say we use the GradeBook class to store grades and compute grade statistics – a clear SRP violation! The video course has a focus on learning the syntax of the C# language, and along the way I teach some OOP concepts as well. In the real world I would have a calculator class that I pass into the gradebook to make the statistics. I would certainly use a calculator class if I expect that the business will ask me to change the calculations in the future. Perhaps next year they will want to drop the bottom three grades and add a standard deviation to the set of statistics. The hardest part of software design is predicting where the future changes in the software will happen. I want to apply the single responsibility principle ruthlessly in those areas where I anticipate change and break the software into smaller bits that work together.
I can’t tell you why there must be a separate class for grade statistics. I can only say having a statistics class feels like the right approach for me. Not everyone will agree, and that’s ok. Remember the context. Someone writing high performance code will loathe the idea of more classes creating more objects. Others will say the solution needs more abstraction. Sometimes you just need to aim for the middle and avoid making obvious mistakes.
Avoid writing classes, methods, or files with too much code. How much is too much? Again, we are back to heuristics. I can tell you I’ve come across ASP.NET MVC controller actions that process an HTTP request using 500 lines of code in a single method. That’s a transaction script with too much code in a single method. The method is difficult to read and difficult to change. I see this scenario happen when a developer focuses on only getting the code to work on their machine so they can move on to the next task. You always want to look at the code you wrote a couple days later and see if it still feels comfortable. If not, the code certainly won’t feel comfortable in 6 months. Break large classes into smaller classes. Break large methods into smaller methods.
Primitive obsession is a pervasive problem in .NET code bases I review. I’ve seen currency values represented as decimals with a string chaser. I’ve seen dates passed around as strings. I’ve seen everything except a widespread effort to improve a codebase using small classes for important abstractions in the system. For example, encapsulating dates in a date-oriented piece of software.
Nothing makes software harder to support than not encapsulating those little bits of information you pass around and use all the time. I’m always amazed how a 5-line class definition can remove repetitive code, make code easier to read and support, and make it harder to do the wrong thing, like add together two values using two different currencies. The link at the beginning of this paragraph points to a post from James Shore, and the post includes one of my favorite quotes (in bold).
“... using Primitive Obsession is like being seduced by the Dark Side. "I'm only dealing with people's ages in this one method call. No need to make an (oh so lame) Age class." Next thing you know, your Death Star is getting blown up by a band of irritating yet plucky and photogenic youngsters.
Best way I know to deal with it is to get over the aversion to creating small classes. Once you have a place for a concept, it's amazing how you find opportunities to fill it up. That class will start small today, but in no time at all it'll be all grown up and asking for the keys to the family car.
Yes, get over the aversion to creating small classes! I too, once had this aversion.
I started learning OOP in the early 90s with C++. Back then, every book and magazine touted the benefits of OOP as reusability, reusability, reusability. It’s as if the only reason to use an OOP language was to make something reusable by other developers.
Looking back, nothing was more damaging to my progress in learning OOP than the idea that everything needed to be reusable. Or, that the only reason to create a new class was if I needed to put code inside for someone else to reuse. I point this out because these days you’ll still find people touting the reusability of OOP constructs, but these people mostly repeat the talking points of yesteryear and do not give any wisdom built on practical experience.
The first rule of the OOP club is to make code usable, not reusable. Reusable code is thinking about the outside world. Usable code is thinking about the inside world, where code must be readable, maintainable, and testable. Don’t make the decision on when to create a class based on the probability of some other developer on your team reusing the class or not. Do feel comfortable creating a new class definition even if the system uses the class only once in the entire code base. Yes, this means you’ll have two classes instead of one. Two files instead of one. Two editor windows instead of one. But, in many contexts, this is the right way.
It took me until around 2004 to recover from the curse of reusability...
When people ask me how to write better code, I always tell them to try unit testing. Nothing taught me more about OOP and software construction than writing tests for my own code. No books, no magazines, no mentors, no videos, no conference talks. The real lessons are the lessons learned from experience with your own code.
When I started unit testing my code in 2003 or 2004 I could see the inflexibility of my software creations. I could see the SRP violations (testing that a class could ___ and ___). I began to see how to use design patterns I had read about but never put into play, like the strategy pattern, and I could see how those patterns helped me achieve the design principles like SRP.
Fast forward to today and I am still a strong proponent of unit testing. Testing will not only help you improve the quality of the software you are building, but also the quality of the code inside. Testing will help you refactor and make changes and improvements to the code. Testing will help you ask questions about your code and find weaknesses in a design.
Testing will help you understand how to build software.
I hope I don’t make software development sound difficult. It’s not. However, improving at software development is an endurance race, not a sprint. There is no substitute for writing code in anger and doing so over a long period of time. If you care about your work, you’ll naturally learn a little bit every day, and every little bit you learn will help you form your own opinions and heuristics on how to build software.
And then, hopefully, you’ll want to learn even more.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#