
I’ve been trying to figure out the most efficient approach to counting matches in a Cosmos DB array, without redesigning collections and documents.
To explain the scenario, imagine a document based on the following class.
class Patient
{
[JsonProperty(PropertyName = "id")]
public string Id { get; set; }
public int[] Attributes { get; set; }
}
I need a query to return patient documents with a count of how many values in the Attributes property match the values in an array I provide as a parameter.
That’s very abstract, so imagine the numbers in the array each represent a patient’s favorite food. 1 is pasta, 2 is beef, 3 is pork, 4 is chicken, 5 is eggplant, 6 is cauliflower, and so on. An Attributes value of [1, 4, 6] means a patient likes pasta, chicken, and cauliflower.
Now I need to issue a query to see what patients think of a meal that combines pasta, chicken, and eggplant (a [1, 4, 5]).
Cosmos provides a number of aggregation and array operators, including an ARRAY_CONTAINS, but to make multiple queries with dynamic parameter values, I thought a user-defined function might be easier.
In Cosmos, we implement UDFs as JavaScript functions. Here’s a UDF that takes two arrays and counts the number of items in the arrays that intersect, or match, so intersectionCount([2,5], [1,2,3,5,7,10]) returns 2.
function intersectionCount(array1, array2) {
var count = array1.reduce((accumulator, value) => {
if (array2.indexOf(value) > -1) {
return accumulator + 1;
}
return accumulator;
}, 0);
return count;
}
One way to use the UDF is to query the collection and return the count of matches with each document.
SELECT p, udf.intersectionCount([4,5], p.Attributes) FROM Patients p
I can also use the UDF in a WHERE clause.
SELECT * FROM Patients p WHERE udf.intersectionCount([1,3], p.Attributes) > 1
The UDF makes the queries easy, but might not be the best approach for performance. You’ll need to evaluate the impact of this approach using your own data and application behavior.
There are numerous benefits to the open source nature of .NET Core. One specific benefit is the ability to look at how teams organize folders, projects, and files. You’ll see common conventions in the layout across the official.NET Core and ASP.NET Core repositories.
Here’s a typical layout:
. |-- src/ |-- test/ |-- <solution>.sln
Applying conventions across multiple repositories makes it easier for developers to move between repositories. The first three conventions I look for in project I work on are:
Having a VS solution file in the root makes it easy for VS developers to clone a repo and open the file to get started. I'll also point out that these repository layout conventions existed in other ecosystems long before .NET Core came along.
In upcoming posts I’ll share some additional folders I like to see in every repository.
Recently I had the opportunity to review the Microsoft Azure compliance offerings and certifications. I did this because some customers want to see proof that Microsoft isn’t running a datacenter out of a 3-car garage in Kirkland.
Compliance docs are difficult to wade through, so while researching I decided I would also binge-watch early seasons of Parts Unknown. Every time I came across the phrase 'policies and process' or a sentence with more than 3 acronyms inside, I could pause and watch chef Bourdain eat tripe stew in an abandoned bomb shelter. There might never be another show like it.
Azure maintains compliance with numerous global, regional, and industry-specific requirements. The Compliance Offerings page is a good starting point to find a specific standard.
One thing to keep in mind is that a standard, requirement, or statement of compliance doesn’t necessarily apply to all of Azure or Microsoft. Microsoft will clearly state the services and products covered by a certification. Some certifications will cover all of Azure, while others might cover a specific product (Office 365 only), or a specific region (Azure US Government or Azure Germany), or a subset of platforms in Azure (Storage and App Services, for example).
Here’s a list of my Azure favorites. Keep in mind I do a bit of work in the U.S. healthcare industry.
ISO 27001 - Compliance with this family of standards demonstrates that Azure follows industry best practices in the policies, procedures, and technical controls for information security.
HIPPA and the HITECH Act - Azure has enabled the physical, technical, and administrative safeguards required by HIPAA and the HITECH Act inside specific services. Microsoft offers a HIPAA BAA as part of the Microsoft Online Services Terms.
HITRUST – the Health Information Trust Alliance maintains a certifiable framework to help healthcare organizations demonstrate their security and compliance.
FedRAMP – Azure offers various compliance offerings for the U.S. Government, including DoD (DISA SRG Level 2, 4, 5) and CMS (MARS-E) specific offerings. In general, these certifications allow federal government and DoD contractors to process, store, and transmit government data. FedRAMP itself is an assessment and authorization process for U.S. federal agencies to facilitate cloud computing.
And now, back to programming …
I worked on a .NET Core console application last week, and here are a few tips I want to pass along.
The McMaster.Extensions.CommandLineUtils package takes care of parsing command line arguments. You can describe the expected parameters using C# attributes, or using a builder API. I prefer the attribute approach, shown here:
[Option(Description = "Path to the conversion folder ", ShortName = "p")]
[DirectoryExists]
public string Path { get; protected set; }
[Argument(0, Description ="convert | publish | clean")]
[AllowedValues("convert", "publish", "clean")]
public string Action { get; set; }
The basic concepts are Options, Arguments, and Commands. The McMaster package, which was forked from an ASP.NET Core related repository, takes care of populating properties with values the user provides in the command line arguments, as well as displaying help text. You can read more about the behavior in the docs.
Running the app and asking for help provides some nicely formatted documentation.

If you are using dotnet to execute an application, and the target application needs parameters, using a -- will delimit dotnet parameters from the application parameters. In other words, to pass a p parameter to the application and not have dotnet think you are passing a project path, use the following:
dotnet run myproject -- -p ./folder
The ServiceProvider we’ve learned to use in ASP.NET Core is also available in console applications. Here’s the code to configure services and launch an application that can accept the configured services in a constructor.
static void Main(string[] args)
{
var provider = ConfigureServices();
var app = new CommandLineApplication<Application>();
app.Conventions
.UseDefaultConventions()
.UseConstructorInjection(provider);
app.Execute(args);
}
public static ServiceProvider ConfigureServices()
{
var services = new ServiceCollection();
services.AddLogging(c => c.AddConsole());
services.AddSingleton<IFileSystem, FileSystem>();
services.AddSingleton<IMarkdownToHtml, MarkdownToHtml>();
return services.BuildServiceProvider();
}
In this code, the class Application needs an OnExecute method. I like to separate the Program class (with the Main entry-point method) from the Application class that has Options, Arguments, and OnExecute.
I’ve been porting a service from .NET to .NET Core. Part of the work is re-writing the Azure Service Bus code for .NET Core. The original Service Bus API lives in the NuGet package WindowsAzure.ServiceBus, but that package needs the full .NET framework.
The newer .NET Standard package is Microsoft.Azure.ServiceBus.
The idea of this post is to look at the changes in the APIs with a critical eye. There are a few things we can learn about the new world of .NET Core.
The old way to construct a QueueClient was to use a static method on the QueueClient class itself.
var connectionString = "Endpoint://.."; var client = QueueClient.CreateFromConnectionString(connectionString);
The new style uses new with a constructor.
var connectionString = "Endpoint://.."; var client = new QueueClient(connectionString, "[QueueName]");
ASPNET core, with its service provider and dependency injection built-in, avoids APIs that use static types and static members. There is no more HttpContext.Current, for example.
Avoiding statics is good, but I’ll make an exception for using static methods instead of constructors in some situations.
When a type like QueueClient has several overloads for the constructor, each for a different purpose, the overloads become
disjointed and confusing. Constructors are nameless methods, while static factory methods provide a name and a context
for how an object comes to life. In other words,
QueueClient.CreateFromConnectionString is easier to read and easier to find compared to examining parameters in the various overloads for the
QueueClient constructor.
The old API offered both synchronous and asynchronous operations for sending and receiving messages. The new API is async only, which is perfectly acceptable in today's world where even the Main method can be async.
The old queue client offered a
BrokeredMessage type to encapsulate messages on the bus.
var message = new BrokeredMessage("Hello!");
client.Send(message);
Behind the scenes,
BrokeredMessage would use a
DataContractBinarySerializer to convert the payload into bytes. Originally there were no plans to offer any type of binary serialization in .NET
Core. While binary serialization can offer benefits for type fidelity and performance, binary serialization also comes
with compatibility headaches and attack vectors.
Although binary serializers did become available with .NET Core 2.0, you won’t find a
BrokeredMessage in the new API. Instead, you must take serialization into your own hands and supply a
Message object with an array of bytes. From
"Messages, payloads, and serialization":
While this hidden serialization magic is convenient, applications should take explicit control of object serialization and turn their object graphs into streams before including them into a message, and do the reverse on the receiver side. This yields interoperable results.
Interoperability is good, and the API change certainly pushes developers into the pit of success, which is also a general theme for .NET Core APIs.
I’ve been mixing up my browser usage over the last year to give MS Edge a closer look. Some pages are noticeably slower in Edge. Looking in the developer tools, the slow pages have thousands of calls to createElement and createDocumentFragment, so I thought it would be interesting to do some microbenchmarks.

With today's stable releases, createElement is twice as fast on Chrome, while createDocumentFragment is an order of magnitude faster.
“An unexpected error occurred” is the least informative error message of all error messages. It is as if cosmic rays have transformed your predictable computing machinery into a white noise generator.
Startup errors with ASP.NET Core don’t provide much information either, at least not in a production environment. Here are 7 tips for understanding and fixing those errors.
1. There are two types of startup errors.
There are unhandled exceptions originating outside of the Startup class, and exceptions from inside of Startup. These two error types can produce different behavior and may require different troubleshooting techniques.
2. ASP.NET Core will handle exceptions from inside the Startup class.
If code in the ConfigureServices or Configure methods throw an exception, the framework will catch the exception and continue execution.
Although the process continues to run after the exception, every incoming request will generate a 500 response with the message “An error occurred while starting the application”.
Two additional pieces of information about this behavior:
- If you want the process to fail in this scenario, call CaptureStartupErrors on the web host builder and pass the value false.
- In a production environment, the “error occurred” message is all the information you’ll see in a web browser. The framework follows the practice of not giving away error details in a response because error details might give an attacker too much information. You can change the environment setting using the environment variable ASPNETCORE_ENVIRONMENT, but see the next two tips first. You don’t have to change the entire environment to see more error details.
3. Set detailedErrors in code to see a stack trace.
The following bit of code allows for detailed error message, even in production, so use with caution.
public static IWebHostBuilder CreateWebHostBuilder(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.CaptureStartupErrors(true) // the default
.UseSetting("detailedErrors", "true")
.UseStartup<Startup>();
4. Alternatively, set the ASPNETCORE_DETAILEDERRORS environment variable.
Set the value to true and you’ll also see a stack trace, even in production, so use with caution.
5. Unhandled exceptions outside of the Startup class will kill the process.
Perhaps you have code inside of Program.cs to run schema migrations or perform other initialization tasks which fail, or perhaps the application cannot bind to the desired ports. If you are running behind IIS, this is the scenario where you’ll see a generic 502.5 Process Failure error message.

These types of errors can be a bit more difficult to track down, but the following two tips should help.
6. For IIS, turn on standard output logging in web.config.
If you are carefully logging using other tools, you might be able to capture output there, too, but if all else fails, ASP.NET will write exception information to stdout by default. By turning the log flag to true, and creating the output directory, you’ll have a file with exception information and a stack trace inside to help track down the problem.
The following shows the web.config file created by dotnet publish and is typically the config file in use when hosting .NET Core in IIS. The attribute to change is the stdoutLogEnabled flag.
<system.webServer>
<handlers>
<add name="aspNetCore" path="*" verb="*" modules="AspNetCoreModule" resourceType="Unspecified" />
</handlers>
<aspNetCore processPath="dotnet" arguments=".\codes.dll"
stdoutLogEnabled="true" stdoutLogFile=".\logs\stdout" />
</system.webServer>
Important: Make sure to create the logging output directory.
Important: Make sure to turn logging off after troubleshooting is complete.
7. Use the dotnet CLI to run the application on your server.
If you have access to the server, it is sometimes easier to go directly to the server and use dotnet to witness the exception in real time. There’s no need to turn on logging or set and unset environment variables. With Azure, as an example, I can go to the Kudu website for an app service, open the debug console, and launch the application like so:
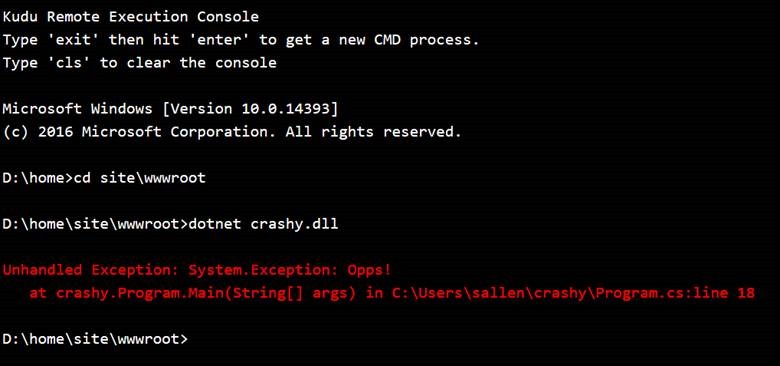
There’s a good chance I’ll be able to witness the exception leading to the 502.5 error and see the stack trace. Keep in mind that with many environments, you might be running in a different security context than the web server process, so there is a chance you won’t see the same behavior.
Debugging startup errors in ASP.NET Core is a simple case of finding the exception. In many cases, #7 is the simplest approach that doesn’t require code or environment changes.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#