
Looking back over the history of the Entity Framework provides some interesting lessons.
Microsoft released the first version of the Entity Framework in August of 2008. One month later, the investment bank of Lehman Brothers filed the largest bankruptcy case in the history of the United States, and thus began the worst global economic downturn since the great depression.
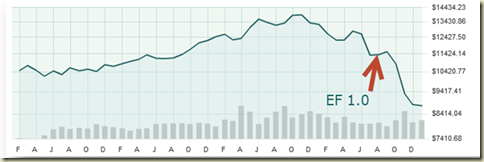
Coincidence?
Probably.
Although the Entity Framework first appeared in 2008, the story begins much earlier. Microsoft has a long history of inventing and re-inventing data-oriented developer tools and frameworks. Applications like FoxPro and Access are long-standing examples, while Visual Studio LightSwitch is a modern specimen. FoxPro and Access were both successful products, and LightSwitch, while still new, shares the same practical attitude to working with data. All these products allow you to build a data centric application with little architectural fuss.
For .NET developers working in C# and Visual Basic, there were several times when we thought we would also see a focused, practical, no-nonsense approach to working with data. While the .NET framework has always provided abstractions like the DataSet and DataTable, these abstractions essentially represented in-memory databases complete with rows, relationships, and views. However, since C# and Visual Basic are both object-oriented programming languages, it would seem natural to take data from a database and place the data into strongly-typed objects with both properties (state) and methods (behavior). One solution we thought was coming from Microsoft was a framework named ObjectSpaces.

ObjectSpaces was described as an object/relational mapping framework, and like all ORM frameworks ObjectSpaces focused on two goals. Goal #1 was to take data retrieved from SQL Server and map the data into objects. Goal #2 was to track changes on objects in memory so when the application asked to save all the changes, the framework could take data from the objects and insert, update, or delete data in the database. In “A First Look at ObjectSpaces in Visual Studio 2005”, Dino Esposito used the above diagram to illustrate these capabilities.
Unfortunately, ObjectSpaces never saw the light of day.
In the spring of 2004, Microsoft announced a delay for ObjectSpaces in order to roll the technology into a larger framework named WinFS. WinFS was one of the original pillars of Longhorn (the now infamous codename for Window Vista), and WinFS promised a much larger feature set compared to ObjectSpaces.
The idea behind WinFS was to provide an abstraction over all sorts of data – relational data, structured data, and semi-structured data. WinFS would allow you to search data inside of Microsoft Money just as easily as tables in SQL Server, calendars in Exchange Server or images on the file system, as well as provide notification, synchronization, and access control services for all data sources, everywhere.
Although some of these ideas had been around since the early 1990s (the Object File System of Microsoft’s Cairo operating system), WinFS was hoping to deliver the vision and offer a quantum leap forward in the way you develop with information.
At the 2005 Professional Developers Conference, Microsoft used the following diagram in WinFS talks. When compared to the previous ObjectSpaces diagram, this diagram is more theoretical and focuses on concepts (Schemas and Services) instead of actions (moving objects from SQL Server and back).

Despite all the talks about quantum leaps in working with data, Microsoft decided it would not ship WinFS as part of Windows Vista, and on June 23, 2006, Microsoft announced that WinFS would not be delivered as a product. Perhaps this was due to the overly ambitious goals of being all things to anything data related, or perhaps it was due to a heavy focus on architectural issues and not enough focus on the practical and mundane. Matt Warren provides an insider’s view in his post “The Origin of LINQ to SQL”.
We on the outside used to refer to WinFS as the black hole, forever growing, sucking up all available resources, letting nothing escape and in the end producing nothing except possibly a gateway to an alternate reality.
From the outside it looks like WinFS was a classic case of taking a specific problem (I need to access a data) and over-generalizing to the point where the original problem gets lost in the solution. Joel Spolsky wrote about this problem in a post entitled “Don’t Let Architecture Astronauts Scare You”.
The Architecture Astronauts will say things like: "Can you imagine a program like Napster where you can download anything, not just songs?" Then they'll build applications like Groove that they think are more general than Napster, but which seem to have neglected that wee little feature that lets you type the name of a song and then listen to it -- the feature we wanted in the first place. Talk about missing the point. If Napster wasn't peer-to-peer but it did let you type the name of a song and then listen to it, it would have been just as popular.
In retrospect, this was a dark time for Microsoft systems and frameworks. Windows Vista delayed shipping until 2007. WPF (aka Avalon) is today not capable of writing genuine Windows 8 applications. WCF (aka Indigo) is under pressure from lightweight frameworks that embrace HTTP, like the ASP.NET Web API. Windows Workflow was subsequently rewritten from scratch after its initial release, and Windows CardSpace is now defunct.
ObjectSpaces failed because it was hauled into a larger vision that was excessively ambitious and over generalized. We’ve seen over the years that the best frameworks start by solving a specific problem, solving it well, and then evolving into something bigger (the shining example being Ruby on Rails). The spirit of agile and lean software development has taught us to continuously deliver something of value, and apply YAGNI ruthlessly. Iteration and shipping bits were not a priority for the WinFS project.
However, you can’t fault Microsoft for thinking big and trying to innovate. Innovation often involves stepping away, trying something different, trying something big, and sometimes failing. Failure, and learning from failure, can lead to new directions and better inventions.
When Microsoft announced the end of WinFS as a product, it also promised to deliver some of the features and ideas encompassed in WinFS through new and different products. One of these products would be the Entity Framework. Would the Entity Framework learn from past mistakes? We’ll take a look in the next post.
A many to many relationship is easy to setup with code first EF. For example, an Author can write many books.
public class Author { public virtual int Id { get; set; } public virtual string Name { get; set; } public virtual ICollection<Book> Books { get; set; } }
And a book can have many authors.
public class Book { public virtual int Id { get; set; } public virtual string Title { get; set; } public virtual ICollection<Author> Authors { get; set; } }
To start a library, all you need is a book set or author set (or both) in a DbContext derived class.
public class LibraryDb : DbContext { public DbSet<Book> Books { get; set; } }
Then the framework will create a database schema with the join table you might expect.

If you want to have a sequence of objects representing every book and author combination, you can use the SelectMany operator to “flatten” a sequence of book authors.
var authorsBooks = db.Books .SelectMany( book => book.Authors, (book, author) => new { AuthorName = author.Name, BookTitle = book.Title });
And the above query generates the following SQL:
SELECT [Extent1].[Id] AS [Id], [Join1].[Name] AS [Name], [Extent1].[Title] AS [Title] FROM [Books] AS [Extent1] INNER JOIN ( SELECT [Extent2].[Author_Id] AS [Author_Id], [Extent2].[Book_Id] AS [Book_Id], [Extent3].[Id] AS [Id], [Extent3].[Name] AS [Name] FROM [AuthorBooks] AS [Extent2] INNER JOIN [Authors] AS [Extent3] ON [Extent3].[Id] = [Extent2].[Author_Id] ) AS [Join1] ON [Extent1].[Id] = [Join1].[Book_Id]
 This year I’ve been to conferences in London, Gothenburg, and Stockholm, and just last week I was in Oslo, Norway for the 5th version of the Norwegian Developers Conference.
This year I’ve been to conferences in London, Gothenburg, and Stockholm, and just last week I was in Oslo, Norway for the 5th version of the Norwegian Developers Conference.
The NDC attracts developers from everywhere in Europe and all around the world because the organizers and planners are dedicated to building the best conference possible. They are a lovely group of people who work hard to make every attendee happy and comfortable. There were also 100 or so speakers in town who also worked hard to make every attendee happy and comfortable.
This year’s NDC delivered over 200 hours of quality content. Unfortunately, the 200 hours of quality content are currently overshadowed by 90 seconds of stupidity. When you have 100 speakers and dozens of sponsors at an event, there is always the risk that someone will do something to damage your reputation.
Please don’t judge the entire conference and its participants on a 90 second video clip. The other 99.9% of the conference provided nourishment for developer brains of all types. I’m sure it will be that way in 2013 and beyond, too.
ECMAScript Harmony is the future of JavaScript, and something you can experiment with using the stable builds of Chrome (my machine is currently running 18.0.1025.152 m, but that is subject to change at any minute).
The first step is going into chrome://flags, and flipping the "Enable Experimental JavaScript" bit.

I'm looking forward to let and proxies.
You might know that the JavaScript we use today has only function scope and global scope. There is no block scope, and the following test will pass without any difficulty (x is scoped to the doWork function, not the block inside the conditional).
test("there is no block scope", function () { "use strict"; var doWork = function() { if(true) { var x = 3; } return x; }; var result = doWork(); strictEqual(result, 3); });
Change the code to use the new let keyword, and the behavior is dramatically different (the return statement in doWork will throw an exception).
test("let has block scope", function () { "use strict"; var error; var doWork = function() { if(true) { let x = 3; } return x; }; try { var result = doWork(); } catch(ex) { error = ex; } strictEqual(error.name, "ReferenceError"); });
Proxies will give JavaScript method_missing and interception / call trap capabilities. I can imagine the data-binding and MVVM frameworks being much less intrusive if they fully embrace proxies. In fact, I can see proxies solving all sorts of problems from data-binding to DOM inconsistencies.
test("Use a proxy", function() { var p = Proxy.create({ get: function(proxy, name) { return "You read " + name; } }); var result = p.fooBar; strictEqual(result, "You read fooBar"); });Now we just need to wait until this code isn't considered "experimental"...
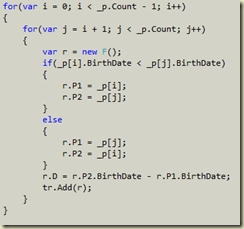 Soon I'll be giving a group of developers some code and asking them to do some refactoring.
Soon I'll be giving a group of developers some code and asking them to do some refactoring.
The bad news is the code is hard to read. Some might say it's intentionally obfuscated, but let's not assume malice right away.
The good news is there are six working unit tests for the code.
There are two goals to the exercise. One goal is to give developers an opportunity to practice refactoring (a Kata, if you will). The way I'd attack the code is to start with some renaming operations, then extract some methods, then perhaps break down the one big class or eliminate a switch statement using patterns. There is no perfect answer.
The larger goal is to convince anyone not entirely sold on the benefit of automated tests how tests can empower them to work with, experiment with, and change existing code - even code they don't completely understand. Although this code was intentionally obfuscated, it's not unlike walking into the code for a complex domain the first time and not understanding why a wurgled customer can blargsmack on Tuesdays if they hold a vorkenhosen status. All domains are nonsense at the start.
If you want to try it too, the code is on github.
It's been just over 8 years since Michael Feathers wrote "The Bar Is Higher Now".
I don't care how good you think your design is. If I can't walk in and write a test for an arbitrary method of yours in five minutes its not as good as you think it is, and whether you know it or not, you're paying a price for it.

It's fascinating to talk to IT professionals from companies around the world and realize what a wide range of workflows are in place. In some shops there are very few automated tests, no automated deployments, and 30 page manuals with instructions for setting up a developer workstation to reach the point where you can begin to work on an application.
On the other side of the gulf there is Amazon (a deployment every 11.6 seconds), Etsy (a new developer commits to production on day 1), and Flickr (they deployed 97 times this week (scroll to the bottom)).
The rapid feedback cycles and agility gained through ruthless automation are a strategic advantage for those companies. I also suspect the developers are happier and far more productive compared to the companies where 20 people are on-call at 4am waiting to help with a new deployment that's been 10 months in the making.
Perhaps the new bar to reach for is this:
If I can't walk in and commit to production on day 1, then you are not as good as you think you are, and you are paying a price for it.
Interesting goal, don't you think?
It's a common to automatically submit a form after a user selects an item from an autocomplete list. The keyword here is "select" – it will lead you to handling the select event of the jQuery UI autocomplete widget.
someInput.autocomplete({
source: data,
select: function () {
form.submit();
}
});
This code will work as long as the user selects an item using the arrow keys and keyboard. The code doesn't work if the user selects an item using the mouse (the proper value doesn't appear in the input or the form submission).
The problem is the select event seems to be designed as more of a pre-processing event. You can implement your own custom selection logic and / or cancel the default logic by returning false from the method. You can also make sure the input is populated before submitting the form.
someInput.autocomplete({
source: data,
select: function (event, ui) {
$(this).val(ui.item.value);
form.submit();
}
});

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#