
It's easy to make a DOM element draggable and droppable with jQuery, but it's not as obvious how to make it stop. It turns out every widget includes a set of standard methods, and one of the standard methods is disable. The only trick you'll learn once you read the documentation is how you invoke the method by passing the method name as a string to the widget's constructor function.
As an example, consider a div you want to be draggable until something happens, like a button click.
<div id="draggable">Drag me around</div> <input type="button" id="stop" value="Stop!" /> <script type="text/javascript"> $(function () { var div = $("#draggable").draggable(); $("#stop").click(function () { div.draggable("disable") .text("I can no longer move"); }); }); </script>
Try it out here: http://jsfiddle.net/NMUxc/
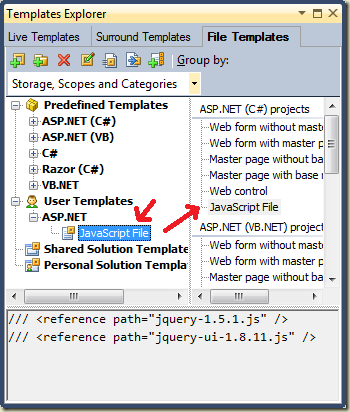 Using Alt+Ins in the Solution Explorer window is one of those ReSharper shortcuts that probably saves me hours over the course of a year (Alt+Ins is the "Create File From Template" command). There is no template out of the box for JavaScript files, but it is easy to add one (or more).
Using Alt+Ins in the Solution Explorer window is one of those ReSharper shortcuts that probably saves me hours over the course of a year (Alt+Ins is the "Create File From Template" command). There is no template out of the box for JavaScript files, but it is easy to add one (or more).
1. Go to ReSharper menu in Visual Studio and select "Live Templates...".
2. In the Templates Explorer dialog, go to the File Templates tab.
3. Right click the User Templates node and select New Template.
4. In the template that opens, the Description field holds the text that will appear in the popup menu for templates. A description like “JavaScript File” would work well.
5. Fill out the default filename field. A name like script.js will work, because you'll be able to change the name when executing the template.
5. Click the available “in everywhere” link below the description. Uncheck “Everywhere” and select “ASP.NET” (so the template is only available for web projects).
6. Add any boilerplate code you'll want in every JavaScript file into the editor window. For example, if you do a lot of work with jQuery, then you might want to go ahead and add the Intellisense references into the template.
/// <reference path="jquery-1.5.1.js" />
/// <reference path="jquery-ui-1.8.11.js" />
7. Finally, to get the template to appear in the Alt+Ins menu, you need to drag and drop the template into one or more of the project areas on the right. In the screen shot above, the template is in the ASP.NET (C#) section.
Taking a few minutes here and there to customize your environment pays a nice return on the investment.
Several people have asked me about using data annotations for validation outside of a UI framework, like ASP.NET MVC or Silverlight. The System.ComponentModel.DataAnnotations assembly contains everything you need to execute validation logic in the annotations. Specifically, there is a static Validator class to execute the validation rules. For example, let's say you have the following class in a console mode application:
public class Recipe { [Required] public string Name { get; set; } }
You could validate the recipe with the following code:
var recipe = new Recipe(); var context = new ValidationContext(recipe, serviceProvider: null, items: null); var results = new List<ValidationResult>(); var isValid = Validator.TryValidateObject(recipe, context, results); if (!isValid) { foreach (var validationResult in results) { Console.WriteLine(validationResult.ErrorMessage); } }
Result: "The Name field is required".
You can construct the ValidationContext class without a service provider or items collection, as shown in the above code, as they are optional for the built-in validation attributes. The Validator also executes any custom attributes you have defined, and for custom attributes you might find the serviceProvider useful as a service locator, while the items parameter is a dictionary of extra data to pass along. The Validator also works with self validating objects that implement IValidatableObject.
public class Recipe : IValidatableObject { [Required] public string Name { get; set; } public IEnumerable<ValidationResult> Validate(ValidationContext validationContext) { // ... } }
Like everything framework related, the Validator tries to provide an API that will work in a number of validation scenarios. I recommend you bend it to your will and build something that makes it easy to use inside your specific design and architecture. A class like the following would be a step towards hiding some complexity.
public class DataAnnotationsValidator { public bool TryValidate(object @object, out ICollection<ValidationResult> results) { var context = new ValidationContext(@object, serviceProvider: null, items: null); results = new List<ValidationResult>(); return Validator.TryValidateObject( @object, context, results, validateAllProperties: true ); } }
This post is a play on Phil's "A Better Razor Foreach Loop". If you aren't familiar with templated delegates in Razor, you can follow the links in Phil's post.
Something I don't like to see in a view is the if null or empty check.
@if (!String.IsNullOrEmpty(User.Identity.Name)) { <span>Logged in as: @User.Identity.Name</span> }
There are a number of ways to remove the check, but the knowledge in Phil's post give you one more option - the HTML helper option.
public static class RazorExtensions { public static HelperResult Maybe(this string @string, Func<object, HelperResult> template) { return new HelperResult(writer => { if (!String.IsNullOrEmpty(@string)) { template(@string).WriteTo(writer); } }); } }
Now the view code can look like this:
@User.Identity.Name.Maybe(@<span>Logged in as: @item</span>)
Better? Or Worse?
 workplace [n] - a place where work is done
workplace [n] - a place where work is done
Over the years I've worked with developers in cubicle farms and private offices, in open spaces and cloistered bureaus. And once there was a basement room across the hall from a mortuary, but I try to forget about that project.
The workplace affects the contentment of its captives, but for some developers the workplace isn't entirely about coffee machines and cafeterias. The workplace is where they spend their hours thinking, creating, and producing. It's not the cubicle, but the computer,the tools, and the code. Bad code gives these developers headaches and anxiety. Good code makes them happy and productive.
Unhappy developers want to change their workplace for the better. I often get questions about how to make this happen. in my experience, change in this area is not something you can do through dictatorship or static code analysis. On a project with hundreds of compiler warnings, you can't just set "treat warnings as errors" and make a place better overnight. You have to guide your peers in a direction that will make them genuinely desire improvement and change. It's not a technical problem, but a sociological problem that requires leadership, and above all, patience.
More than a few developers who are unhappy with their workplace join groups related to software craftsmanship. It's unfortunate that the manifesto for this movement uses an ornamental typeface on Victorian looking paper. These subtle gratuities help to drive the misconception that the members are elitists who build over-engineered solutions.
There is a fine line between over-engineering and improvement, and the debates between "delivering business value" versus "crafting perfect software" always reminds me of the TV shows where celebrity chefs save failing restaurants. All the restaurants on these shows seem to have have the same fundamental problems.
1. They take shortcuts, like microwaving crab cakes.
2. They have disorganized, dirty kitchens.
3. They use frozen pre-cooked food instead of fresh ingredients.
All of the above are done in the name of "delivering value", or putting food on a plate. Software development is similar because there are many shortcuts we can take, but unlike bad food, the effects of bad software are difficult to measure. Once the cooks at the failing restaurant see how better habits lead to better food, the kitchen become a happier, productive workplace.
The key to turning things around is getting people to care. This can't happen by flaming during a code review or rewriting someone else's code. It can happen by catching the attention and curiosity of other people in the workplace and showing them there is a world where people aim for self improvement. This can happen with inclusive events like a "lunch and learn" or book club (try running a book club with the Clean Code book, for example).
Not everyone will attend, but you have to stay positive. Changing the way people think about themselves and their work is a long process that can only work if there is the opportunity for regular communication and introspection.
If you want to simulate an exception from an IQueryable data source, be careful about when the exception is thrown. As an example, let's use the following interface.
public interface IContext { IQueryable<Person> People { get; set; } }
To simulate an IllegalOperationException from the data source, you might setup a mock with the following code.
var mockContext = new Mock<IContext>(); mockContext.SetupGet(c => c.People) .Throws<InvalidOperationException>();
But, the mock will throw the exception as soon as something touches the People property. With a real data source, the exception won't happen until the query executes. Think about the misbehavior the mock would create with the following code.
var query = context.People .Where(p => p.BirthDate.Year > 2000); try { foreach (var p in query) { Console.WriteLine(p.Name); } } catch (InvalidOperationException ex) { // ... }
To exercise the catch logic, you'll need to defer the exception until the query executes. You might think this is as easy as waiting till GetEnumerator is invoked to throw the exception.
var queryable = new Mock<IQueryable<Person>>(); queryable.Setup(q => q.GetEnumerator()) .Throws<InvalidOperationException>(); var mockContext = new Mock<IContext>(); mockContext.SetupGet(c => c.People) .Returns(queryable.Object);
Unfortunately, the above code doesn't work. To have LINQ operators like Where, Select, and OrderBy work properly requires more plumbing behind the IQueryable object. The above code fails with the first call to Where.
Here is a hand rolled class that works on my machine.
public class ThrowingQueryable<T, TException> : IQueryable<T> where TException : Exception, new() { public IEnumerator<T> GetEnumerator() { throw new TException(); } IEnumerator IEnumerable.GetEnumerator() { return GetEnumerator(); } public Expression Expression { get { return Expression.Constant(this); } } public Type ElementType { get { return typeof(T); } } public IQueryProvider Provider { get { return new ThrowingProvider(this); } } class ThrowingProvider : IQueryProvider { private readonly IQueryable<T> _source; public ThrowingProvider(IQueryable<T> source) { _source = source; } public IQueryable CreateQuery(Expression expression) { return CreateQuery<T>(expression); } public IQueryable<T> CreateQuery<T>(Expression expression) { return _source as IQueryable<T>; } public object Execute(Expression expression) { return null; } public TResult Execute<TResult>(Expression expression) { return default(TResult); } } }
You can use it like so:
var mockContext = new Mock<IContext>(); mockContext .SetupGet(c => c.People) .Returns(new ThrowingQueryable<Person, InvalidOperationException>());
I like Kzu's take on building unit-testable domain models with EF code first. I've been playing around with some of the same ideas myself, which center around simple context abstractions.
public interface IDomainContext { IQueryable<Restaurant> Restaurants { get; } IQueryable<Recipe> Recipes { get; } int SaveChanges(); void Save<T>(T entity); void Delete<T>(T entity); }
It's easy to mock an IDbContext, but I wanted a fake. My first brute force implementation had loads of messy problems in the Save and Delete methods. Here is an excerpt.
class FakeDbContext : IDomainContext { ... HashSet<Restaurant> _restaurants = new HashSet<Restaurant>( HashSet<Recipe> _recipes = new HashSet<Recipe>(); public void Save<T>(T entity) { var type = entity.GetType(); if (type == typeof(Restaurant)) _restaurants.Add(entity as Restaurant); if (type == typeof(Recipe)) _recipes.Add(entity as Recipe); }
... }
The problem is how each new entity type requires changes inside almost every method. In a classic case of overthinking, I thought I wanted something like EF's Set<T> API, where I can invoke Set<Recipe>() and get back HashSet<Recipe>. That's when I went off and built something to map Type T to HashSet<T>, based on .NET's KeyedCollection.
class HashSetMap : KeyedCollection<Type, object> { public HashSet<T> Get<T>() { return this[typeof(T)] as HashSet<T>; } protected override Type GetKeyForItem(object item) { return item.GetType().GetGenericArguments().First(); } }
The HashSetMap seemed to help the implementation of the FakeDbContext - at least I deleted all the if statements.
private HashSetMap _map; public FakeDbContext() { _map = new HashSetMap(); _map.Add(new HashSet<Restaurant>()); _map.Add(new HashSet<Recipe>()); } public void Save<T>(T entity) { _map.Get<T>().Add(entity); }
I was thinking this was clever, which was the first clue I did something wrong, and eventually I realized the idea of keeping a separate HashSet for each Type was ludicrous. Finally, the code became simpler.
class FakeDbContext : IDomainContext { HashSet<object> _entities = new HashSet<object>(); public IQueryable<Restaurant> Restaurants { get { return _entities.OfType<Restaurant>() .AsQueryable(); } } public IQueryable<Recipe> Recipes { get { return _entities.OfType<Recipe>() .AsQueryable(); } } public void SaveChanges() { ChangesSaved = true; } public bool ChangesSaved { get; set; } public void Save<T>(T entity) { _entities.Add(entity); } public void Delete<T>(T entity) { _entities.Remove(entity); } }
Usage:
[SetUp] public void Setup() { _db = new FakeDbContext(); for (int i = 0; i < 5; i++) { _db.Save(new Recipe()); } } [Test] public void Index_Action_Model_Is_Three_Recipes() { var controller = new RecipeController(_db); var result = controller.Index() as ViewResult; var model = result.Model as IEnumerable<Recipe>; Assert.AreEqual(3, model.Count()); }

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#