
Previously on OdeToCode I posted about tracking down an AspNetCore build error. Once I realized the access denied message came from the ProgramData\Microsoft\Crypto\RSA\MachineKeys folder, I went searching for reasons why this might happen, and to find possible solutions. Here are some observations based on my research.
During my NodeJS days I developed a strange vocalization tic. The tic manifested itself every time I found an answer on Stack Overflow suggesting sudo as the answer to a security problem. As in, "just use sudo npm install and you'll be done". The tic resurfaced during my research for access denied messages around MachineKeys. From GitHub issues to Stack Overflow and Microsoft support forms, nearly everyone suggests the developer give themselves "Full Control" of the folder and consider the job finished. There is no root cause analysis or thought given to the idea that although "Full Control" might work, it still might be the wrong answer.
Here is an example where the Full Control solution is encouraged, favorited, and linked to from other issues that encourage developers to use the same work around.
Given that the MachineKeys folder is not in an obvious location for storing user specific data, and given the folder name itself implies the contents are for all the users on the machine, and given the folder can contain the private keys of cryptographic key pairs, I immediately dismissed any answer suggesting full control or taking ownership of the folder.
I also realized during my research that not many people run into this specific problem. The few I found who did some real analysis were pointing fingers at Windows updates. And indeed, this particular machine accepts insider builds of Windows. For those not brave enough to use insider builds, I can say that insider updates are both frequent and are similar to playing with commercial grade fireworks. It's fun when they work, but you are only one misfire away from burning down your house.
I began to suspect my access denied error was a problem with my Windows configuration, and not with the AspNetCore builds or .NET tools. I tried the build for the same commit on two other machines, and both were successful.
Two out of three is a consensus in distributed computing, so now I was certain I had a configuration problem, probably caused by Windows Update incorrectly applying inherited security attributes. I started looking for how to fix the problem.
In my research I came across the support document titled "Default permissions for the MachineKeys folders" A promising title. There is even some rousing prose in the summary section implying how MachineKeys is a special folder.
The MachineKeys folder stores certificate pair keys for both the computer and users. ... The default permissions on the folder may be misleading when you attempt to determine the minimum permissions that are necessary for proper installation and the accessing of certificates.
I was waiting for the document to rattle off the exact permissions setup, but after an auspicious opening the document spirals into darkness with language and terms from Windows Server 2003. It is true that MachineKeys requires special permissions, but I found it easier to compare settings on two different computers than to translate a 16-year old support document.
On my problem machine, the MachineKeys folder inherited permissions from the parent folder. These permissions gave Everyone read permissions on the folder and all files inside, and this is why al.exe would fail with an access denied error. Given that the folder can contain private keys from different users, these setting are also dangerous. The folder shouldn't inherit permissions, we need to set special permissions.
The first step in fixing the mess through the GUI is to right-click the folder, go to Properties, go to the Security tab, click Advanced at the bottom of the dialog, click "Disable inheritance", and then "Remove all inherited permissions from this object".

Now there is a clean slate to work with. Use the Add button to create a new permissions entry selecting Everyone as the principal. In the Basic Permissions group, select only Read and Write. Make sure "Applies to" has "This folder only" selected.

Also add the Administrators group, and allow Full control for this folder only. You'll know the right settings are in place when the regular security tab shows "Special Permissions" for both the Everyone group and Administrators.

These special permissions allow average users to write into the folder, and then read and delete a file they write. But, they cannot list the contents of the folder or touch files from other users (although admins will have the ability to delete files from other users).
Solving security problems requires care and patience. But, I feel better having a working AspNetCore build without compromising the security settings on my machine.
Building AspNet Core from source is straightforward, unless, like me, you run into strange errors. My first build compiled over 600 projects successfully, but ended up failing and showing the following message.
Build FAILED.
ALINK : error AL1078: Error signing assembly -- Access is denied. [...\LocalizationSample.csproj]
ALINK : error AL1078: Error signing assembly -- Access is denied. [...\LocalizationWebsite.csproj]
ALINK : error AL1078: Error signing assembly -- Access is denied. [...\RazorPagesWebSite.csproj]
ALINK : error AL1078: Error signing assembly -- Access is denied. [...\BasicTestApp.csproj]
0 Warning(s)
4 Error(s)
I first noticed that all four failures were because of AL.exe, a.k.a ALINK, the little known assembly linker that ships with .NET. Compared to a linker in the world of C++, the .NET linker is an obscure tool that is rarely seen unless a build needs to work with satellite assemblies generated from .resx files, or sign an assembly with a public/private key pair.
The next bit I noticed was that the first two projects involved localization, so I was sure the build errors were some sort of problem with satellite assemblies or resource files. Unfortunately, the error message access is denied is short on helpful details. I went looking for obvious problems and verified that projects existed in the correct directories, and that no files were missing.
In need of more information, I decided to create a detailed log of of my AspNetCore build. Building all of AspNetCore requires running a build script, one of build.cmd, build.ps1, or build.sh, depending on your OS and mood. All of these scripts accept parameters. For example, build -BuildNative will build the native C/C++ projects, which includes the AspNetCoreV2 IIS module. The default is to only -BuildManaged. You can also thunk MSBuild parameters through the build script, so I used the following to create a binary log of detailed verbosity, and avoided writing to the console to save time:
build.cmd -bl -verbosity:detailed -noconsolelogger
All AspNetCore build output goes into an artifacts folder, including the binary log. To view the binary log I use MSBuildStructureLog, a tool I've written about previously.
A word of warning - AspNetCore build logs are not the kind of logs that you can pack into an overnight bag and sling over your shoulder. If you want to open and view the logs I recommend a machine with at least 16GB of RAM, but 32 is better. The machine needs to handle a process with 10+ GB committed or else be sucking mud.
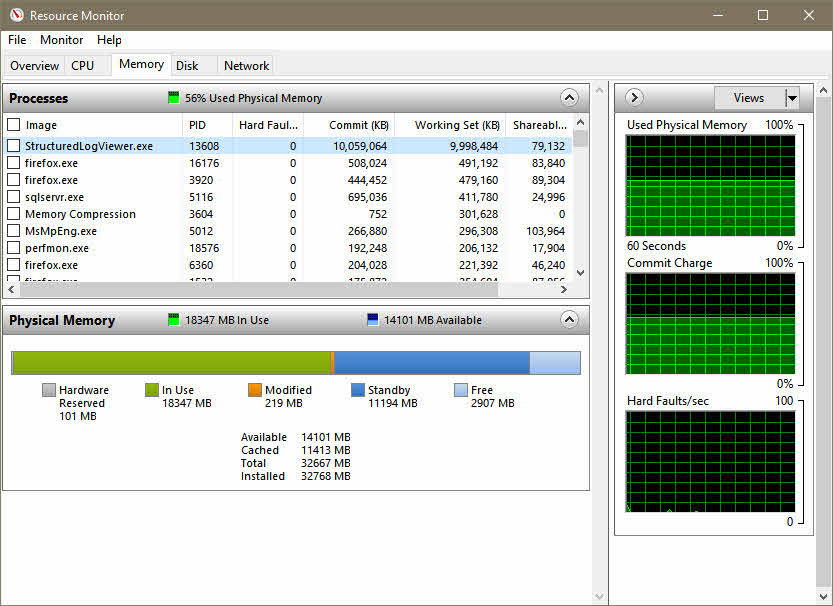
Once the build log loads, it is easy to find build errors.
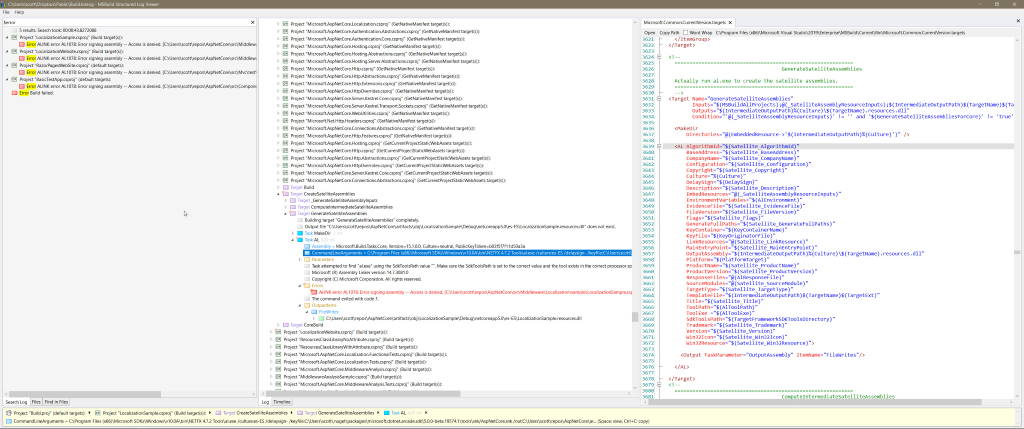
The command line for each of the 4 build errors looked like the following:
CommandLineArguments = ...\al.exe /culture:es-ES /delaysign- /keyfile: and so on...
I tried the command line myself, and sure enough, there is an access denied error.
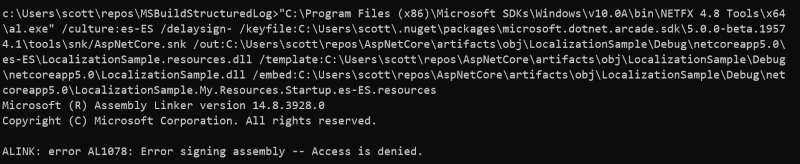
The good news, I thought to myself, was that I can easily reproduce the build error without running the entire build. The bad news, I thought to myself, was that I still don't know what resource is denying access. Time to bring in more tools.
The Sysinternals Suite has been invaluable for debugging over the years. Process Monitor in particular is the first tool that comes to mind when I need to track down file system activity.
If you've ever worked with procmon, you'll know the tool can capture an overwhelming amount of data. The first thing to do is to add one or more filters to the capture. In the screen shot below I am only showing file system activity for any process named al.exe. With the filter in place I can execute the command line, and sure enough, procmon shows the access denied error.
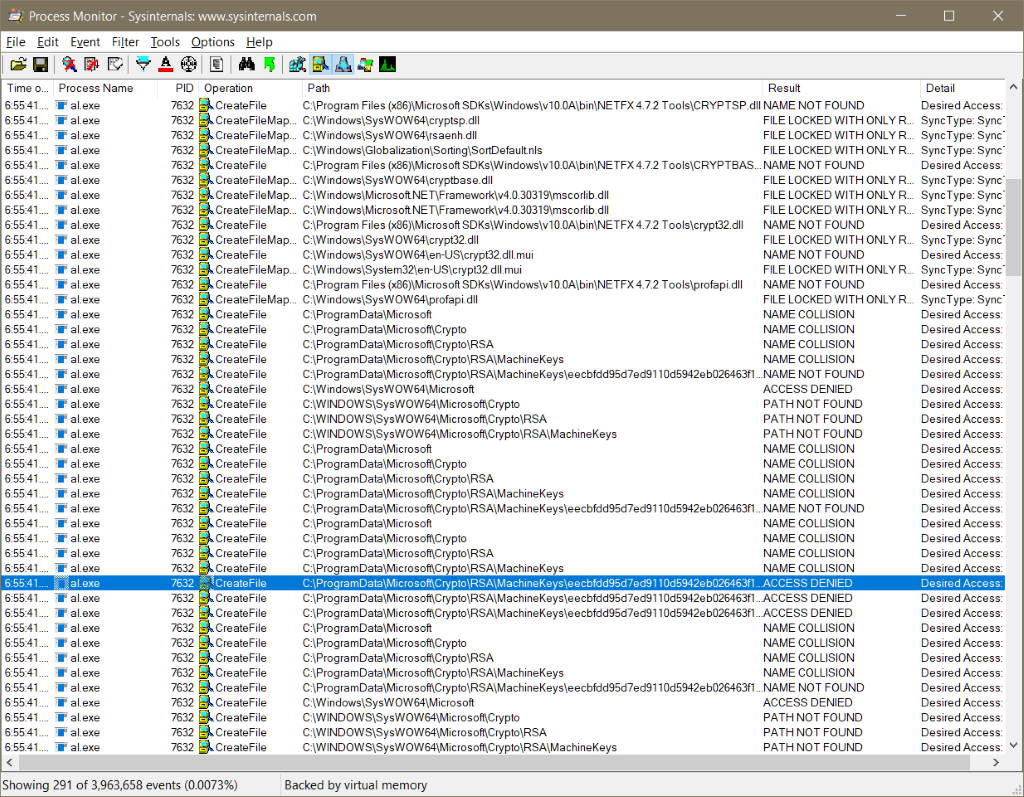
The access denied message occurs on a file inside the ProgramData\Microsoft\Crypto\RSA\MachineKeys folder. It appears to me, based on my limited knowledge of the Windows crypto API, that al.exe is trying to write an ephemeral private key into the machine keys folder, but my user account doesn't have permission to create the file.
Now I know why the build is failing, but there is no clear solution to fix the problem.
Stay tuned for the next blog post where I will reveal the unexciting solution to this problem in a stupendously boring fashion. Sneak preview: the solution does not involve sudo or changing folder permissions to give my account full control...
Finally! I've used binary literals in real code. This feature, and the digits separator have been good additions to the C# language.
public static byte[] BreakIntoTwos(byte value)
{
var result = new byte[4];
result[0] = (byte)((value & 0b1100_0000) >> 6);
result[1] = (byte)((value & 0b0011_0000) >> 4);
result[2] = (byte)((value & 0b0000_1100) >> 2);
result[3] = (byte) (value & 0b0000_0011);
return result;
}
I thought <Nullable>enable</Nullalble> would be the star of the C# 8 show by now, but in day to day work I'm finding that switch expressions are stealing the show.
Size = 1 + Operands.Size;
OpCode = Bits.BottomFive(memory.Bytes[0]);
Operation = OpCode switch
{
0x01 => new Operation(nameof(JE), JE, hasBranch: true),
0x0A => new Operation(nameof(TestAttr), TestAttr, hasBranch: true),
0x0F => new Operation(nameof(LoadW), LoadW, hasStore: true),
0x09 => new Operation(nameof(And), And, hasStore: true),
0x10 => new Operation(nameof(LoadB), LoadB, hasStore: true),
0x14 => new Operation(nameof(Add), Add, hasStore: true),
0x0D => new Operation(nameof(StoreB), StoreB),
_ => throw new InvalidOperationException($"Unknown OP2 opcode {OpCode:X}")
};
I was never a fan of switch statements, but switch expressions have the ability to reduce nasty, nested, cyclomatically complex code into a tabular, declarative display of elegant simplicity.
Another example:
var instruction = memory.Bytes[0] switch
{
0xBE => DecodeExt(memory),
var v when Bits.SevenSixSet(v) => DecodeVar(memory),
var v when Bits.SevenSet(v) => DecodeShort(memory),
_ => DecodeLong(memory)
};
gRPC is a framework you can use in ASP.NET Core 3 to build APIs. The gRPC framework offers both advantages and disadvantages compared to the HTTP based APIs we’ve always been able to build using ASP.NET Core controllers. But, there’s one important aspect of gRPC that is often overlooked in the wave of 3.0 evangelism you read in blogs, hear in podcasts, and see in videos and conferences:
gRPC services won't work in IIS or Azure App Services.
IIS and App Services constitute a non-trivial share of production environments for AspNet Core, so it is regrettable that some developers discover late in the development process that gRPC won’t work for them. Only recently has the documentation for gRPC started to include a warning message:
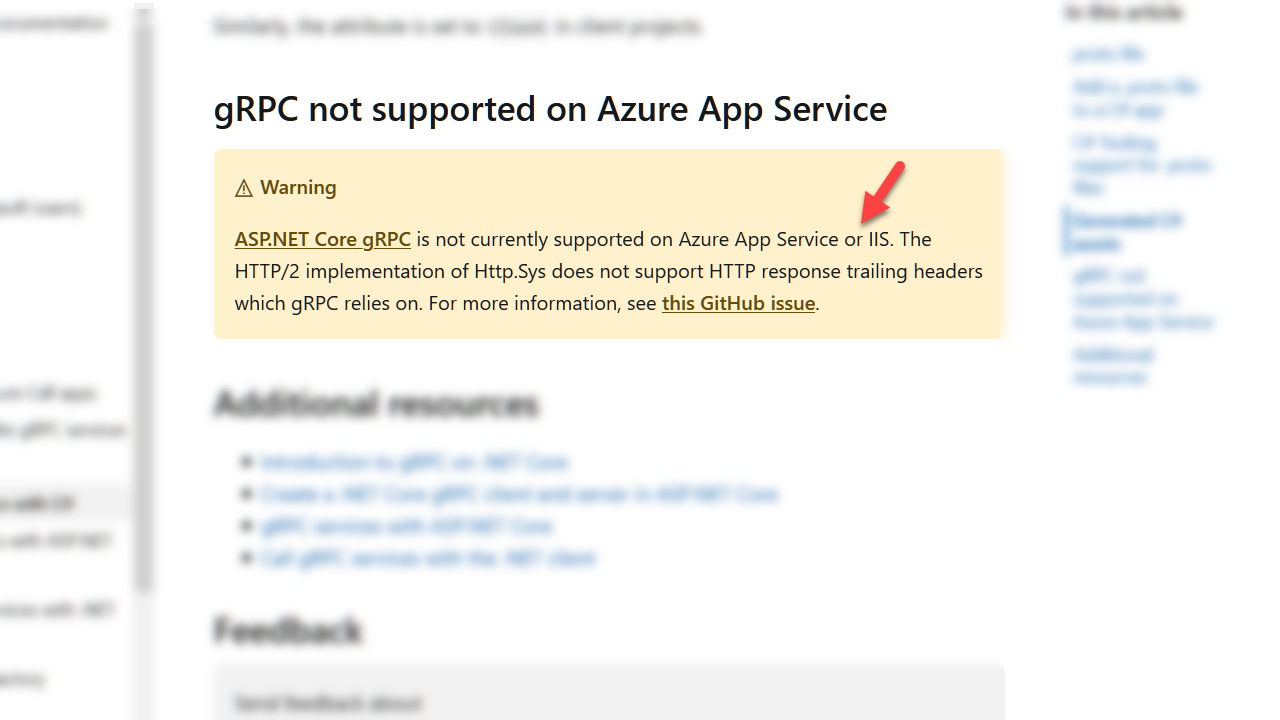
The warning itself is misleading. IIS and App Services have two different problems.
It’s true that IIS cannot current host a gRPC service because http.sys doesn’t support trailing headers. gRPC relies on trailing headers to communicate vital information, like call status. The first sign of trouble here appears when you scaffold a new gRPC service project using Visual Studio. AspNet Core projects typically include the option to develop using IIS Express, but this launch option is not present after running the gRPC scaffolding.
In Azure, Windows based App Services use IIS and have the same http.sys limitation. However, you can’t circumvent the problem by hosting in a Linux or using a custom container. The App Service front-end terminates incoming TLS connections before forwarding unencrypted messages to your App Service worker. Your gRPC service will refuse to communicate over http and return only HTTP 426 Upgrade Required errors.
There’s currently no timetable I can find for either IIS or App Services to make a workable environment for gRPC services. Fortunately, there are other options for hosting gRPC services in Azure and the cloud including using Kestrel directly in a virtual machine or in a Kubernetes cluster.
The bigger issue for me is the reoccurring problem where Microsoft messaging around new AspNet Core features doesn’t consider the realities of production. Another example of this problem was with the original .NET Core release. While Microsoft was promoting the record performance benchmarks of AspNet Core, all of us hosting AspNet Core on IIS were seeing performance numbers worse than MVC 5. The confusion took a long time to clear up.
UseNodeModules is a NuGet package I put together a few years ago. The package gives you an easy way to install middleware for serving content directly from the node_modules folder in an ASP.NET Core project.
public void Configure(IApplicationBuilder app)
{
app.UseNodeModules(maxAge: TimeSpan.FromSeconds(600));
}
The idea is that during development you can use npm to manage all your client-side dependencies and you can use those dependencies immediately instead of setting up a process to copy files into the wwwroot folder. In production, you might use environment tag helpers to serve files you’ve bundled during a build, or to use minified files from a CDN. During development, however, you don’t have to wait for bundling, minification, and copying to occur.
Here's an example with Bootstrap 4. In development we'll serve directly from the node_modules folder. In any other environment we'll serve a minified file from a CDN, but with fallbacks to the node_modules folder in case the CDN is unavailable.
<environment include="Development">
<link href="~/node_modules/bootstrap/dist/css/bootstrap.css" rel="stylesheet" />
</environment>
<environment exclude="Development">
<link rel="stylesheet" href="//ajax.aspnetcdn.com/ajax/bootstrap/4.3.1/css/bootstrap.min.css"
asp-fallback-href="~/lib/bootstrap/dist/css/bootstrap.min.css"
asp-fallback-test-class="sr-only" asp-fallback-test-property="position" asp-fallback-test-value="absolute" />
</environment>
Be aware that dotnet publish will not copy the node_modules folder to the published output directory. You can change this behavior by adding the following to the .csproj file.
<ItemGroup>
<Content Include="node_modules\**" CopyToPublishDirectory="PreserveNewest" />
</ItemGroup>
A nice side benefit of the above code is how Visual Studio users will also see node_modules in the Solution Explorer view. Otherwise, the folder is hidden by Visual Studio, which I’ve never understood.
Thanks to Shawn Wildermuth for the help!
Today's release of .NET Core 3 is significant. By supporting Windows desktop development and dropping support for the full .NET framework, v3 makes a statement - not only is .NET Core here to stay, but .NET Core is the future of .NET.
Included in all the fanfare is Microsoft's new web UI framework by the name of Blazor. Blazor gives us the ability to write interactive UIs using C# instead of JavaScript and it works using one of two different strategies. The first strategy compiles C# code into WebAssembly for execution directly in the browser. This WebAssembly strategy is still experimental and won't see a supported release until next year.
The second strategy sends client events to the server using SignalR. C# code executes on the server and produces UI diffs, which the framework sends back to the client over SignalR for merging into the DOM.
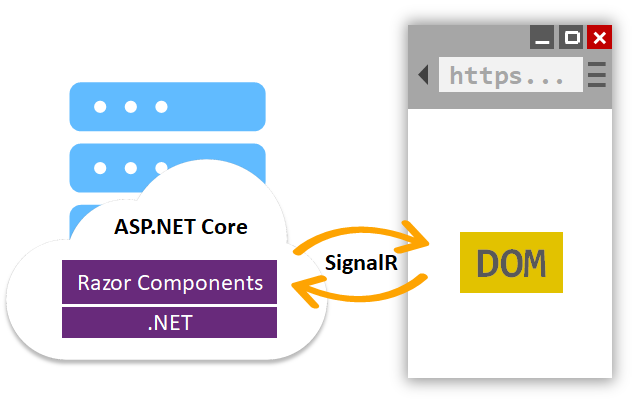
Most people won't see much risk in moving to .NET Core these days. Blazor, on the other hand, doesn't have a clear path to success.
Client-side development is a subjective experience. There are developers who embrace the organic JavaScript ecosystem. There are also developers who are desperate to see Blazor succeed because the messiness of working with disparate package managers, compilers, and frameworks du jour is raw and frustrating. These individuals don't necessarily dislike JavaScript, but they do feel vastly more comfortable and productive using a language like C# and tools designed to work seemlessly end to end.
These developers typically stick to building applications using server-rendered HTML because the environment is simple and productive. Yes, there is always a push to be more interactive, depending on the type of application being built, but sometimes a well-placed JS component will work well enough and avoid the complexities of building a full blown SPA.
For these teams that have avoided the Angulars, Reacts, and Vues – is now the time to jump into client UI using Blazor?
One of the first arguments against Blazor is the "look what happened to Silverlight" argument, a reference to Microsoft's last successful client UI framework. A framework Microsoft killed just as the framework was reaching peak popularity.
I personally don't consider what happened with Silverlight to have any impact on the decision to use Blazor, or not. I say this partly because Microsoft is a different company today compared to 10 years ago, but also because every Microsoft product and framework faces the same risk. Microsoft will always be inventing frameworks, then promoting and evangelizing those frameworks as the solution to all software problems. Microsoft will continue investing in those frameworks until one day, something better comes along, and suddenly, with no fanfare or formal announcement, you'll find the framework dead on the vine.
This isn't just Microsoft's history for decades, but a chronic condition of the software industry. Ask WCF customers.
The bigger risk, I think, is in the execution strategies. The WebAssembly approach, where code executes in the browser, is the solution we want to see working, but WASM is still in preview because of technical issues. When the WASM approach does arrive, we still need to evaluate how well the approach works. How much does the browser need to download? How good is DOM interop from C# code? How will the compiler work with all the evolving interfaces of the W3C? Will the development experience be as iterative as today's hot-reload experience? There's many questions to answer.

With WebAssembly on hold, we are left with the server-side execution model. But, there's something about this model that doesn't pass a sniff test. We've been told over the years that stateful web applications are evil. We've been told over the years that the network is slow, unreliable, and not to be trusted. Suddenly, Blazor enters the room and talks about storing state on the server and running click events over the network. The mind explodes with questions. Does this even scale? Can it be trusted? What happens to my mobile users in a train tunnel?
Everything about this first version is wrapped in caution tape. Everyone wants to make a prototype to see how it works. Nobody is ready to bet the farm.
Remove stateful prerendering is an innocuous title, but the implications for Blazor are considerable.
To summarize the issue – each Blazor component requires some space on the server. If you request too many components, the server can run out of space. Thus, malicious users can leverage Blazor to DOS your servers.
Issue 12245 is the type of issue that comes to mind when "run client logic on the server" is listed as a Blazor feature. How can there not be issues with security and scale?
Like with many security problems, the solution is to eliminate a useful feature. Now, you can't use Blazor to render a component that depends on a piece of state or a parameter. The only state the component can use is state the component creates once the component connects to the server.
Unfortunately, the solution eliminates many component use cases. Let's say I don't want to build a SPA. I want to add interactivity to specific pages in an app. To do so, I'll create components that can render an account by ID, or show the score for games on a specific date. With stateful prerendering it was easy to pass an ID or a date to a component and let the component go out and fetch whatever data it needs.
No stateful prerendering means there is no direct mechanism for passing parameters to a component. Components will need to dig parameters out of a URL, or use JSInterop to fetch parameters from state embedded in a page. Although both are possible, it does make some component scenarios impossible, and almost all scenarios become a bit more hacky.
In the end, I believe WebAssembly is the model we want to use with Blazor. I'm curious to see if the server-side model, with it's inherent limitations, will continue to live once WebAssembly arrives. The server model will probably be easier for developers to use, but we can already see how limitations will hinder widespread adoption.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#