
There has been some discussion lately about the rise of C++ to first class citizen status in .NET country. Unfortunately, C++ still has one major flaw: the preprocessor.
The criminally insane have used the C++ preprocessor over the years to pervert, subvert, and convert otherwise good source code into an atrocious collection of tokens and symbols. I was witness to one of these atrocities in graduate school. One semester I came across a professor who was a Pascal zealot and book author. Although C++ was the official language of the curriculum, Dr. Pascal used the magic of the preprocessor to make everything look Pascal-ish. The code resembled the following sample from The Daily WTF:
procedure SelectFontIntoDC(Integer a) begin
declare fonthandle fh;
if (gRedraw is not false) then begin
fh = CreateFontIndirect(gDC);
SelectObject(gDC, fh);
DeleteObject(fh);
end;
end;
It is this sort of leftist brainwashing that keeps conservative parents awake at night after they drop little Johnny off in front of the freshman dorm. Pascal is Pascal, and C++ is C++ - let’s not pretend otherwise with subversive preprocessor definitions.
Sure, C++ is feature rich, but it also carries more baggage than a Four Seasons hotel porter. Jump on the C# fashion wagon – there is still room in the hold to pick up more luggage.
If you are a fan of Design By Contract, then you’ll find Wes Haggard’s thesis work, nContract, to be an impressive package. nContract allows you to specify contract validations by decorating types and their members with custom attributes. For example:
[Pre("value != null")]
[Post("Contents.Count == old.Contents.Count + value.Length")]
public virtual void Append(string value)
{
stringBuilder.Append(value);
numberOfChars += value.Length;
}
Custom attributes are the perfect place for contract specifications. The pre-condition and post-condition for the Append method will be forever bound to the method and packaged into the metadata. The Append method itself remains clean and easily readable.
To actually perform the contract checking, nContract code-gens a subclass for the component using CodeSmith ( CodeSmith appears to be moving from freeware to commercial, so this might be a bit of a spoiler).
Another core feature in nContract is the ability for clients to configure contract checking in a granular way using configuration files (no recompilations needed), and the ability to hook in a custom assertion handler.
I’ve always been a fan of design by contract, and a bit envious of the Eiffel crowd who get design by contract built-in….
Like Ben @ CodeBetter, I admire the power behind the Office API. We finally have some customers buying into the promise of smart clients, and it is amazing to see the amount of functionality available through the object model of Word, Excel, and the rest of the family.
But, after reviewing the code, I still think it sucks. The rough edges of interop poke out in every corner, and the constant appearance of Sytem.Object in parameter lists and return values ruins the discoverability.
object currentDateBookmark = "CurrentDate";
Word.Range range =
thisDocument.Bookmarks.get_Item(ref currentDateBookmark).Range;
"Quit whining", I hear you say. "There is a leaning curve involved". Yes, there is a leaning curve, but even once you have the vocabulary down there is unattractive code involved.
CategoryList = commandBar.Controls.Add(
Office.MsoControlType.msoControlComboBox,
missing,
missing,
missing,
(object)true
) as Office.CommandBarComboBox;
Ok, this is unattractive C# code. Make no doubt about it, Office automation currently looks best in VB.NET.
Having troubles getting pair programming started in your shop?
Do you feel it would be easier to breed giant pandas in captivity then it would be to get Pat and Gunther to program together?
You need the DICA solution!
DICA is a revolutionary new drug manufactured in the best underground pharmaceutical laboratories available, and is guaranteed* to kick start an Xtreme Pair Programming Xperience in your office. For just $99.99 we will send you the DICA Starter Kit, which includes 100 doses of DICA! We are pratically giving it away! Enough DICA for over 800 hours of Xtreme Pair Programming! Just listen to this customer testimonial:
My dev lead called me into the office and told me my coffee was tainted with this stuff he called DICA. I was like, “Are you legally allowed to do this to me, dude?”. When I went back to my desk, suddenly there was my pair partner. He had four arms and we started cutting code like mad. I could see design patterns leaping out of the software. Beautiful patterns ... patterns everywhere.”
-Eddie Flablestick of San Francisco, CA.
Bring pair programming to your company today! DICA is the safe** and affordable way!
Wait! There’s more! Order now and we will throw in a lava lamp for free!
Automated voice ordering systems are standing by!
* Not a money back guarantee
** Side effects can include nausea, increased heart rate, and the manifestation of long lasting psychoses. If pair programming continues for more than 16 hours, consult a physician.
The following code shows some interesting differences when executing under the 1.1 and 2.0 runtimes.
class Class1
{
static void Main(string[] args)
{
try
{
for (Int32 i = 0; i < Int32.MaxValue; i++)
{
SqlConnection connection = new SqlConnection(connectionString);
connection.Open();
Thread.Sleep(30);
Console.WriteLine(i.ToString());
}
}
catch(Exception ex)
{
Console.WriteLine(ex.Message);
}
Console.WriteLine("Finished");
}
static string connectionString = "Data Source=.;Integrated Security=True";
}
The program eventuallys throw an exception under both versions of the runtime:: Timeout expired. The timeout period elapsed prior to obtaining a connection from the pool. This may have occurred because all pooled connections were in use a nd max pool size was reached..
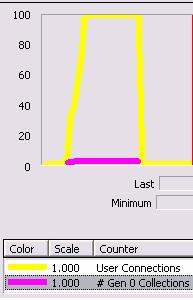
The difference is, under 1.1 the program makes roughly 140 iterations, while under 2.0 the program makes roughly 900+ iterations. In both cases max pool size defaults to 100 connections. Perfmon shows the follwing, where the yellow line is the SQL Server statistic for # of actual connections, and the purple line tracks gen 0 garbage collections. When the yellow line hits 100 - program go boom.
 |
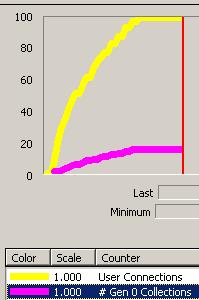 |
| 1.1 | 2.0 |
Under 1.1 the garbage collector finishes 3 gen 0 collections before the runtime throws an exception, under 2.0 the collector finishes 16 gen 0 collections. I wouldn’t think these collections are triggered by memory pressure, so I'm wondering what other logic may lay beneath the connection pooling mechanism in 2.0. It’s hard to see what is happening under the hood because Reflector is misbehaving on my beta 2 install. Anyone have ideas?
I try to avoid join and query hints in T-SQL.
Adding a hint to a query is like buying a tailored suit. As long as your body doesn’t change - the suit will look great, but a little variation in your weight can turn a great suit into a disaster. Likewise, a query hint might boost the performance of a query on today’s data – but what about next week’s (or the next client’s) data? A hint might handcuff and prevent the query optimizer from formulating a better query plan.
In my experience - join hints, index hints, and FORCE ORDER hints appear when SQL Server doesn’t understand the data as well as the person writing the query. To avoid hints, try to ‘describe’ the data to SQL Server using indexes and statistics. Also make sure to apply UNQIUE constraints on any field that will contain unique values. Proper database design will go a long way to avoiding the need for join hints.
Non-clustered indexes in SQL Server contain only the values for the columns they index, and then a ‘pointer’ to the row with the rest of the data. This is similar to the index in a book: the index contains only the key word, and a page reference you can turn to for the rest of the information. Generally, the database will have to follow pointers from the index to other pages (known as bookmark lookups) to gather all the information required for a query.
If, however, the index contains all of the columns requested in a query, the savings in disk IO can be tremendous - the query engine doesn’t have to follow pointers around and seek out other pages on disk. We call these types of queries covered queries, because all of the columns needed for the query are covered by the index.
Covering a query with an index can be a significant performance boost, and in the BI applications I work with we often use this optimization. The caveat to this optimization is that the larger the index key, the more work the database has to do to compare keys. Measurements must be taken to ensure the proper balance. Also, index keys are limited to a maximum size of 900 bytes and 16 columns in SQL Server.
SQL 2005 introduces a nice little feature: included columns. Included columns will allow us to pack data values into a non-clustered index without increasing the key size of the index. Included columns also don’t count towards the 900 byte key limit or the 16 maximum columns. Example:
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
The above index has a small key size (just the PostalCode column), but will be able to cover any query using the other address fields. We will still pay a price in disk space, but it is now possible to design more effecient non-clustered indexes in SQL 2005.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#