
After considering the three rules and creating a baseline, an entire team can work with a database whose definition lives safely in a source control repository. The day will come, however, when the team needs to change the schema. Each change creates a new version of the database. In my plan, the baseline scripts created a schema change log to track these changes.

By "change", I mean a change to a table, index, key, constraint, or any other object that requires DDL, with the exception of views, stored procedures, and functions. I treat those objects differently and we'll cover those in the next post. I also include any changes to static data and bootstrap data in change scripts.
Alternatives
Before jumping into an example, I just wanted to point out there are many ways to manage database changes and migrations. Phil Haack describes his idempotent scripts in Bulletproof Sql Change Scripts Using INFORMATION_VIEWS. Elliot Smith and Rob Nichols are database agnostic with Ruby Migrations. If you know of other good articles, please post links in the comments. Again, the goal is to manage change in the simplest manner possible for your project.
Example, Please
The team just baselined their database that includes a Customers table, but now wants to add a new column to store a Customer's shoe size. They also realized their OrderState table, a lookup table that include the values 'Open', and 'Shipped', now needs a new value of 'Canceled'. They would need to create a schema change script that looks like the following. Notice I can include as many changes as needed into a single script.
File: sc.01.00.0001.sql
Whoever writes this change script will test it thoroughly and against a variety of test data, then commit the change script into source control. The schema change is officially published. The schema change will start to appear in developer workspaces as they update from source control, and on test machines as new builds are pushed into QA and beyond.
It's good to automate database updates as ruthlessly as possible. Ideally, a developer, tester, or installer can run a tool that looks at the schema version of the database in the SchemaChangeLog table, and compares that version to the available updates it finds in the form of schema change scripts that reside on the file system. Sorting files by name will suffice using the techniques explained here. Command line tools work the best, because you can use them in build scripts, developer machines, and install packages. You can always wrap the tool in a GUI to make it easy to use. Here's the output I recently saw from a schema update tool (some entries removed for brevity):
Connected to server .
Connected to database xyz
Host: SALLEN2 User: xyz\sallen
Microsoft SQL Server 2005 - 9.00.3054.00 (Intel X86)
Schema history:
05.00.0000 initial-install on Dec 13 2007 11:26AM
05.00.0001 sc.05.00.0001.sql on Dec 13 2007 11:26AM
05.00.0002 sc.05.00.0002.sql on Dec 13 2007 11:26AM
...
05.00.0012 sc.05.00.0012.sql on Dec 13 2007 11:26AM
05.01.0000 sc.05.01.0000.sql on Dec 13 2007 11:26AM
05.01.0001 sc.05.01.0001.sql on Dec 13 2007 11:26AM
...
05.01.0019 sc.05.01.0019.sql on Dec 13 2007 11:26AM
Current version:
05.01.0019
The following updates are available:
sc.05.01.0020.sql
sc.05.01.0021.sql
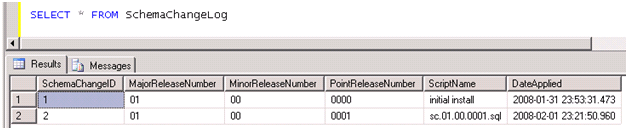
Once a developer runs the schema change in this post, they should see the following in the schema change log:
Schema Change Rules and Tips
Once a script is published into source control, it cannot be changed! Once someone updates their database with an update script, they should never have to run the same script on that same database.
The responsibility of updating the SchemaChangeLog table should reside with the tool that applies the updates. This way, the tool can ensure the script runs to completion before the recording the update into the change log.
Always backup a production database before applying a change script. If a change script happens to fail with an error, you can at least get the database back into a known state.
Some people will wonder what happens if multiple developers are all working on change scripts at the same time. Fortunately, the source control repository is a great mediator. I can't add an update script with the same name as your update script – I'll have to rev my version number if you beat me to the commit by a few seconds.
Of course, changes are not just about schema changes. You also have to write the code to migrate data. For instance, if for some reason we moved the ShoeSize column from the Customers table to the CustomerDetails table, the update script will also need to move and preserve the data. Data manipulation is often the trickiest part of change scripts and where they need the most testing.
Summary
Managing change with your database yields a great many benefits. Since the schema change scripts are in source control, you can recreate your database as it looked at any point in time. Is a customer reporting a bug on build 3.1.5.6723? Pull the source code tagged or labeled with that version number and run the baseline, then all schema change scripts included in the tag. You now have the same database and have a much better chance to recreate the bug. Also, changes move from development to test, and ultimately into production in a consistent, orderly, and reproducible manner.
I've skipped over quite a few nitty-gritty details, but I hope you get the general idea. I've used this approach for years and its worked well. Still, I feel the approach is a bit long in the tooth and I'm looking for ways to improve. Feedback is appreciated. What do you think?
Coming up next – managing views and stored procedures.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#