
I had a star schema and an XML document of creamy data to stuff inside. What’s the best approach to updating the dimension tables with new values? There are many tried and true approaches to evaluate.
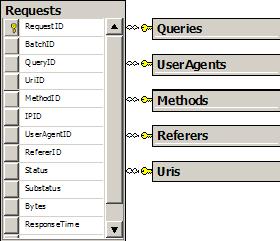
Let’s take the specific case of the Referers table. This table stores a RefererID, and a Referer string. I have an XML document full of Request elements, each with a Referer attribute. I needed to look at each element and find any Referer values that do not exist in the database to insert only new values.
<Request Date="2005-11-15T07:59:59Z"
Uri="/Articles/rss.aspx"
Referer=""
Status="200"
ResponseTime="609"
/>
One approach would be to parse the file, lookup each referrer in the database, and execute an INSERT statement if the value isn’t found. This approach uses at least two database roundtrips per request, so processing a large number of records will crawl.
Another approach is to pass the entire document to SQL Server 2005 and work with the new XML capabilities.
CREATE PROCEDURE [Stats].[ImportReferers]
@WebStatistics AS XML
AS
BEGIN
SET NOCOUNT ON;
WITH XMLNAMESPACES(DEFAULT 'https://odetocode.com/wfStatsImport.xsd')
INSERT INTO Stats.Referers
SELECT DISTINCT request.value('@Referer', 'varchar(900)')
FROM @WebStatistics.nodes('//Request') AS Request(request)
LEFT JOIN Stats.Referers R ON
R.Referer = request.value('@Referer', 'varchar(900)')
WHERE R.Referer IS NULL
END
In SQL 2005 there are at least two approaches to transforming XML into a rowset. Once approach is OPENXML, but the code still gets a messy with pre and post-processing. A cleaner approach is to take advantage of the native XML data type in 2005, which offers query(), value(), exist(), modify() and nodes() methods. The nodes() method is just what I needed to transform XML elements into a relational table. The value() method can pull out an attribute to act like a column. All I needed then was a LEFT JOIN to find just the Referer values that didn’t already exist. Performance has been acceptable for a server running on Virtual PC.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#