
When a system needs more resources, we should favor horizontal scale versus vertical scale. In this document, we’ll look at scaling with some Microsoft Azure specifics.
When we scale a system, we add more compute, storage, or networking resources to a system so the system can handle more load. For a web application with customer growth, we’ll hopefully reach a point where the number of HTTP requests overwhelm the system. The number of requests will cause delays and errors for our customers. For systems running in Azure App Services, we can scale up, or we can scale out.
Scaling up is replacing instances of our existing virtual hardware with more powerful hardware. With the click of a button in the portal, or a simple script, we can move from a machine with 1 CPU and 1.75 GB of memory to a machine with double the number of cores and memory, or more.
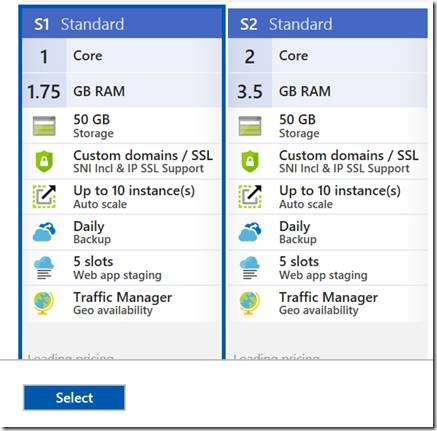
We sometimes refer to scaling up (and down) as vertical scaling.
Scaling out is adding more instances of your existing virtual hardware. Instead of running 2 instances of an App Service plan, you can run 4, or 10. The maximum number depends on the pricing tier you select.
Scaling out and in is what we call horizontal scaling.
Horizontal scaling is the preferred scale technique for several reasons.
First, you can program Azure with rules to automatically scale out. Likewise, you can also apply rules to scale in when the load is light.
Secondly, horizontal scale adds more redundancy to a system. Commodity hardware in the cloud can fail. When there is a failure, the load balancer in front of an app service plan can send traffic to other available instances until a replacement instance comes on-line. We want to test a system using at least two instances from the start to ensure a system can scale in the horizontal direction without running into problems, like when using in-memory session state. Make sure to turn off Application Request Routing (ARR) in the app service to make effective use of multiple instances. ARR is on by default, meaning the load balancer in front of the app service will inject cookies to make a user’s browser session sticky to a specific instance.
Thirdly, compared to vertical scaling, horizontal scale offers more headroom. A scale up strategy can only last until we reach the largest machine size, at which point the only choice is to scale out. Although the maximum number of instances in an App Service plan is limited, using a DNS load balancer like Azure Traffic manager allows a system to process requests across multiple app service plans, and the plans can live in different data centers, providing additional availability in the face of disaster and practically an infinite horizontal scale.
There are some types of systems which will benefit more from a scale up approach. A CPU bound system using multiple threads to execute heavy processing algorithms might benefit from having more cores available on every machine. A memory bound system to manipulate large data structures might benefit from having more memory available on every machine.
The only way to know the best approach for a specific system is to run tests and record benchmarks and metrics.
Scale up and scale out are two strategies to consider for scaling specific components of a system. Generally, we consider these two strategies for stateless front-end web servers. Other areas of a system might require different strategies, particularly networking and data storage components. These components often require a partitioning strategy.
Partitioning comes into play when an aspect of the system outgrows the defined physical limits of a resource. For example, an Azure Service Bus namespace has defined limits on the number of concurrent connections. Azure Storage has defined limits for IOPS on an account. Azure SQL databases, servers, and pools have defined limits on the number of concurrent logins and database transaction limits.
To understand how partitioning works, and the nuances of choosing a partitioning strategy, consider the following scenario.
You own a transportation company. You have a contract to transport a party of 75 people from downtown to the airport at exactly 9:30 in the morning. You own a fleet of buses, but each bus only holds 50 people. Everyone must leave at the same time, and you must let every person know which bus they will ride on before they arrive.

The above scenario is an example of a situation that requires partitioning. Since there is no vehicle with a capacity of 75, you’ll need to partition the 75 individuals across 2 vehicles. That’s the easy part to see. The harder part is coming up with a partitioning strategy so you’ll know where everyone will go, and where to find them later. You could partition by the first letter of last name (A-M on one bus, N-Z on another), or age range, or gender. We must understand our data to choose an effective, scalable partitioning strategy for our data.
Likewise, if you need more concurrent connections than a single Service Bus endpoint can provide, you’ll need to add more endpoints and partition your tenants, customers, and client applications across the endpoints.
Many database systems refer to partitioning as sharding, and in databases systems there are often additional concerns to consider when selecting a partitioning strategy. ACID transactions may be impossible, or at least incredibly expensive, to enforce across partitions. Thus, you also need to consider the behavior and consistency requirements of a system when considering a partitioning strategy. For SaaS, the tenant ID is often part of the partitioning strategy.
There is no single best solution for scale. We need to amalgamate our business requirements and cost factors with an understanding of our data and an understanding of how our system behaves at run time to determine the best strategy for scale. Here are some steps that will help.
1. Understand your business requirements, specifically when it comes to cost per tenant and the desired availability levels. Will you have a service level agreement with your customers? Cost factors and SLAs influence the amount of availability to build into the system. Availability influences the amount of redundancy to build into a system, and redundancy will influence cost and can influence scalability since more resources are in play.
2. Understand how the system behaves under load before the load arrives. Also, understanding how the system responds to different scale strategies. Load testing is vital to understanding both of these aspects of the system. You need to know the baseline behavior of the system under a normal load, and where the system fails when the load increases. How will your system behave if give it more headroom on a single machine versus more instances of the same machine? Although replicating real user behavior in a load test is difficult, knowing approximate answers to these questions will help you devise a cost effective strategy to scale.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#