
Rob ran into some lazy load problems in his MVC Storefront and later proclaimed:
"…if you set any Enumerable anything as a property, it's Count property will be accessed when you load the parent object. This negates using any deferred loading for any POCOs, period"
Rob thought this was a problem with .NET in general, but I was suspicious. Veeery suspicious. I downloaded Rob's latest bits and found some interesting behavior.
Based on the screen shot of the call stack that Rob posted, it appeared LINQ to SQL was doing some type conversions. If you poke around the classes mentioned in the call stack, you'll eventually wander into a GenerateConvertToType method that uses LCG to build dynamic methods. Just based on the opening conditional logic, I thought Rob might solve his problem by using LazyList<T> for his business object properties, too (whether or nor he'd want to is a different question), so I modified his Category class for a few experiments to see what would really lazy load.
This was in hopes that LINQ to SQL wouldn't feel compelled to do a conversion via List<T>. I just needed to tweak the query to set all four properties.
This experiment failed in a stunning fashion, because none of the Product properties lazy loaded – they all eagerly populated themselves full of real product objects. Hmmm.
Watching SQL Profiler, I started to wonder why there were soooo many queries running. Sure, the stuff wasn't lazy loading but the queries were flying by quicker than eggs at a Steve Ballmer talk. Yet, the code that was kicking off the whole process was just looking for a single category:
That problem turned out to be in Rob's WithCategoryID extension method.
By taking an IEnumerable<T> parameter, the extension method was forcing the query to execute and then doing all the ID checks using LINQ to Objects. Just switching over to IQueryable<T> made the method a lot more efficient, and the number of queries came down tremendously.
Back to the original problem, which was a bit of a mystery because I've been able to lazy load collections using IEnumerable<T> and IQueryable<T>. After some more fiddling, I began to suspect the query itself. The query uses a correlated subquery by virtue of the fact that the range variable c is used inside the query for products (c.CategoryID). I'm guessing that LINQ to SQL felt compelled to take care of all the work in one fell swoop. Instead of using a subquery, I presented LINQ to SQL with a method call that pushed the needed parameter (c.CategoryID) onto the stack, and made things slightly more readable in the process.
And voila! Three of the properties (ProductsQueryable, ProductsEnumerable, ProductsLazy) would lazy load their Products from the database. Only the original IList<Product> property would eagerly fetch data. From what I can decipher in the grungy code, when LINQ to SQL sees it needs to assign to an IList<T>, and it doesn't have an IList<T>, it eagerly loads a new List<T> and copies those elements into the destination. At least, that's my theory.
Knowing what I know now, I could tell Rob to stick with IList<T> as his property type, but to make sure he has IList<T> on both sides of the assignment in his projection (and tuck the product query into a method call). In other words, use the following to create the LazyList<T> - LINQ to SQL won't load up Products during some wierd type conversion:
Conclusion? Beware of mismatched types, particularly with IList<T>, and watch out for eager execution with correlated subqueries.
Microsoft has a long history of being visual. They've made quite a bit of money implementing graphical user interfaces everywhere – from operating system products to database servers, and of course, developer products. What would Visual Studio be if it wasn't visual?
And oh how visual it is! Visual Studio includes a potpourri of visualization tools. There are class diagrams, form designers, data designers, server explorers, schema designers, and more. I want to classify all these visual tools into one of two categories. The first category includes all the visual tools that build user interfaces – the WinForms and WebForms designers, for instance. The second category includes everything else.
Visual tools that fall into the first category, the UI builders, are special because they never need to scale. Nobody is building a Windows app for 5,000 x 5,000 pixel screens. Nobody is building web forms with 5,000 textbox controls. At least I hope not. You can get a pretty good sense of when you are going to overwhelm a user just by looking at the designer screen.
Visual tools that fall into the second category have to cover a wide range of scenarios, and they need to scale. I stumbled across an 8-year-old technical report today entitled "Visual Scalability". The report defines visual scalability as the "capability of visualization tools to display large data sets". Although this report has demographics data in mind, you can also think of large data sets as databases with a large number of tables, or libraries with a large number of classes - these are the datasets that Visual Studio works with, and as the datasets grow, the tools fall down.
Here is an excerpt of a screenshot for an Analysis Services project I had to work with recently:
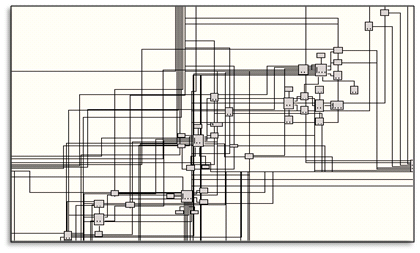
Here is an excerpt of an Entity Data model screenshot I fiddled with for a medical database:
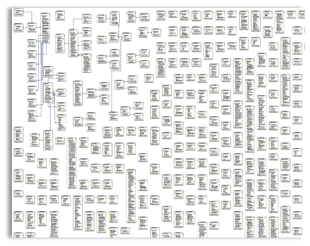
These are just two samples where the visual tools don't scale and inflict pain. They are difficult to navigate, and impossible to search. The layout algorithms don't function well on these large datasets, and number of mouse clicks required to make simple changes is astronomical. The best you can do is jump into the gnarly XML that hides behind the visual representation.
I'm wondering if the future will see a reversal in the number of visual tools trying to enter our development workflow. Perhaps textual representations, like DSLs in IronRuby, will be the trick.
Nothing can compare to the Real Power of programming with attributes. Why, just one pair of square brackets and woosh – my object can be serialize to XML. Woosh – my object can persist to a database table. Woosh – there goes my object over the wire in a digitally signed SOAP payload. One day I expect to see a new item template in Visual Studio – the "Add New All Powerful Attributed Class" template: *
Which begs the question – could there ever be a way to separate attributes from the class definition?**
* Put down the flamethrower and step away - I'm kidding.
**This part was a serious question.
LINQ to SQL requires you to start with a database schema.
Not true – you can start with code and create mappings later. In fact, you can write plain-old CLR object like this:
… and later either create a mapping file (full of XML like <Table> and <Column>), or decorate the class with mapping attributes (like [Table] and [Column]). You can even use the mapping to create a fresh database schema via the CreateDatabase method of the DataContext class.
LINQ to SQL requires your classes to implement INotifyPropertyChanged and use EntitySet<T> for any associated collections.
Not true, although foregoing either does come with a price. INotifyPropertyChanged allows LINQ to SQL to track changes on your objects. If you don't implement this interface LINQ to SQL can still discover changes for update scenarios, but will take snapshots of all objects, which isn't free. Likewise, EntitySet provides deferred loading and association management for one-to-one and one-to-many relationships between entities. You can build this yourself, but with EntitySet being built on top of IList<T>, you'll probably be recreating the same wheel. There is nothing about EntitySet<T> that ties the class to LINQ to SQL (other than living inside the System.Data.Linq namespace).
LINQ to SQL has limitations and it's a v1 product, but don't think of LINQ to SQL as strictly a drag and drop technology.
Daily Standup Transcription 06 May 2008 1300 Zulu
Time In 00:02:34.66
"… so, yesterday I continued the refactorafication of some classes. The job isn't easy, but I'm going to work hard and continue the collaborativity with my programming partner. Together, we will eliminate the evil of legacy code operating inside the code base.
I know it's been slow going, but we did misundestimerate the threat of static ... static … statictistical dependencies in the code.
Now, if you'll excuse me, I need to get back to work for the great customers of this company."
Time Out 00:02:54.29
 After my last post, someone asked me if the "portable" repository pattern was really a good idea. He was referring to the fact the LINQ queries in the MVC Storefront and Background Motion applications would sometimes execute against in-memory collections (for unit testing), while the rest of the time the queries would execute against a relational database. Isn't there a huge risk in developers not knowing if the software really works with the database?
After my last post, someone asked me if the "portable" repository pattern was really a good idea. He was referring to the fact the LINQ queries in the MVC Storefront and Background Motion applications would sometimes execute against in-memory collections (for unit testing), while the rest of the time the queries would execute against a relational database. Isn't there a huge risk in developers not knowing if the software really works with the database?
I don't think of the repository as a "portability" layer, although since it is an abstraction layered on top of the data access code it can provide some nice indirections, like the ability to switch the persistence store. Is this risky? Sure, there is always some element of risk in portability. Just ask anyone who has written code with a portable UI toolkit, or in HTML for that matter. You don't know what is going to happen until the 1s and 0s hit the silicon.
But …
That's not the job for unit tests. Ideally, you'll have some other tests to verify what happens when the "production" code runs.
Before continuing, I must say that in the last post I neglected to tell you that the brainy Mindscape team and Andrew Peters are responsible for the Background Motion web site, and the code that powers the site. Make sure to visit the site and marvel at the beauty of New Zealand, then drop into the Mindscape blogs. Everyone - let's hear it for New Zealand!
You can write a LINQ query that works fine against in-memory collections, but that can fail spectacularly when you swap in a remote LINQ provider. Here is an obvious example:
This query is happy to execute using LINQ to Objects, but it fails with an exception if LINQ to SQL is sitting behind the sequence (NotSupportedException: Method 'Boolean IsNullOrEmpty(System.String)' has no supported translation to SQL).
Those types of problems are easy to spot in automated integration testing because exceptions are relatively easy to track down. The real risk is in the queries that don't flame out in spectacular fashion, but execute successfully with slight variations. Here is one example:
This query wants to get distinct list of zip codes and states for all our customers, and order the list by state. Works perfectly with LINQ to objects, and executes successfully in LINQ to SQL. Just one tiny problem you might observe in the generated SQL:
Notice the distinct (pardon the pun) lack of an ORDER BY clause. If the upper layers were expecting the results sorted by State then we have problems.
It turns out that LINQ to SQL throws out an inner OrderBy operator when the Distinct operator comes into play. This could be for several reasons, but the most likely reason is DISTINCT and ORDER BY have an uneasy relationship in ANSI SQL (it's not just MS SQL). You can read more about this on Jeff Smith's blog: SELECT DISTINCT and ORDER BY, and there is another good explanation here: Some Common Mis-conceptions about DISTINCT.
One also has to wonder if Distinct might reorder the results in its quest to remove duplicates - it's not explicitly documented that it doesn't. In this case, it's better to forego the query comprehension syntax and make the pipeline of operators more explicit:
This forces LINQ to SQL to generate a safe query with the expected results.
Is there risk? Sure – and it's not just in LINQ to SQL. Any multi-target technology runs the same risk. You just need an awareness and safety net (in the form of tests) to mitigate the risk.
There are two applications on CodePlex that are interesting to compare and contrast. The MVC Storefront and Background Motion.
MVC Storefront is Rob Conery's work. You can watch Rob lift up the grass skirt as he builds this application in a series of webcasts (currently up to Part 8). Rob is using the ASP.NET MVC framework and LINQ to SQL. The Storefront is a work in progress and Rob is actively soliciting feedback on what you want to see.
At the it's lowest level, the Storefront uses a repository type pattern.
The repository interface is implemented by a TestCatalogRepository (for testing), and a SqlCatalogRepository (when the application needs to get real work done). Rob uses the repositories to map the LINQ to SQL generated classes into his own model, like the following code that maps a ProductImage (the LINQ generated class with a [Table] attribute) into a ProductImage (the Storefront domain class).
Notice the repository also allows IQueryable to "float up", which defers the query execution. The repositories are consumed by a service layer that the application uses to pull data. Here is an excerpt of the CatalogService.
Controllers in the web application then consume the CatalogService.
Another interesting abstraction in Rob's project is LazyList<T> - an implementation of IList<T> that wraps an IQueryable<T> to provide lazy loading of a collection. LINQ to SQL provides this behavior with the EntitySet<T>, but Rob is isolating his upper layers from LINQ to SQL needs a different strategy. I'm not a fan of the GetCategories method in CatalogService – that looks like join that the repository should put together for the service, and the service layer itself doesn't appear to add a tremendous amount of value, but overall the code is easy to follow and tests are provided. Keep it up, Rob!
The Background Motion (BM) project carries significantly more architectural weight. Not saying this is better or worse, but you know any project using the Web Client Software Factory is not going to be short on abstractions and indirections.
Unlike the Storefront app, the BM app uses a model that is decorated with LINQ to SQL attributes like [Table] and [Column]. BM has a more traditional repository pattern and leverages both generics and expression trees to give the repository more functionality and flexibility.
Notice the BM repositories will "float up" a deferred query into higher layers by returning an IQueryable, and allow higher layers to "push down" a specification in the form of an expression tree. Combining this technique with generics means you get a single repository implementation for all entities and minimal code. Here is the DLinqRepository implementation of IRepository<T>'s Find method.
Where FindOne can be used like so:
BM combines the repositories with a unit of work pattern and consumthines both directly in the website controllers.
The Background Motion project provides stubbed implementation of all the required repositories and an in-memory unit of work class for unit testing, although the test names leave something to be desired. One of the interesting classes in the BM project is LinqContainsPredicateBuilder – a class whose Build method takes a collection of objects and a target property name. The Build method returns an expression tree that checks to see if the target property equals any of the values in the collection (think of the IN clause in SQL).
If you want to see Background Motion in action, check out backgroundmotion.com!
 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#