
The HTML editor in VS2008 was killing me on pages using the fancier DevExpress controls. The editor would freeze after every keystroke. Responsiveness was so bad I started using a plain text editor to make changes to those pages.
Thankfully, a hotfix is now publically available. I tested an early version of the hotfix, and it made Visual Studio 2008 a happy place to work in again.
This wasn't a problem with the DevExpress controls, by the way. Their controls get better and better with each release. My recent favorite is the ASPxPivotGrid, which can slice and dice data from a relational database, or an OLAP database. Try the online demos for yourself.
Previous entries:
If you are not familiar with branching and merging, I'd suggest Eric Sink's excellent Source Control HOWTO. My preferred branching practice is "branch for release". New development work takes place in the mainline, or the trunk of the repository. As a product nears release, schema changes become rare and code churn slows. At this point, the team creates a branch for the release. New feature development resumes in the trunk with schema changes and all. The branch receives only bug fixes. The team generally merges fixes from the branch into the trunk.
How do schema changes work in this scenario?
In The Words Of Run-D.M.C.
It's tricky.
Schema changes in a branch require some care and thought. The technique I use of forward-only, run--once schema change scripts has some issues when it comes to branches. This is certainly an area you'll want to think about when devising your schema management process.
In my case, I bet that schema changes in a branch will be rare. Like most things in our field, it's all about the tradeoffs. If you use a more aggressive branching strategy (like branch per feature), this approach doesn't work so well. Other strategies (like Ruby Migrations) can move forward or backward with changes (as you don't make irreversible changes).
The Scenario
Let's say the team baselined the database at version 01.00.0000, and wrote 45 change scripts during feature development (01.00.0001 to 01.00.0045). Feature development is done, and the product is near a 1.0 release, so a 1.0 branch is created (note: the schema version and database version don't need to coincide at all).
At the point of branching, I create a new baseline for the database. In this case, a baseline of 01.01.0000 or 02.00.0000 is fine - I just want to rev either the major or minor version number. Let's say we use 02.00.0000 for the purpose of discussion. This new baseline goes into the trunk. All new database installs (from the trunk) just run this new baseline script, as it should produce the same database as the original baseline + the 45 change scripts. I also check in an empty 02.00.0000 schema change script so that all existing databases, when updating to a new build on this code, are now "version 2" databases.
Now, imagine the team working ahead and creating 2 schema change scripts in the trunk. These changes are 02.00.0001 and 02.00.0002. At this point a bug is found in the branch, and the bug requires a schema change to fix. Ugh!
Back in the branch, the team creates schema change 01.00.0046, and fixes the bug with a combination of code and change script. All is well for production type systems that are only receiving stable builds, because those databases have never seen a v2.0 change script. We simply update those systems with the new v1.0 build. The branch build includes and applies the 46th change script. All is well, at least in the world of 1.0.
What About the Mainline?
To get this fix into the mainline, there are two options. Well, actually there are an infinite number of options to consider depending on how you apply your updates, but here are two options:
With option #1 you have to be careful because any database that updated to v2.0 will not take the 46th change script from the branch (unless you write your tools differently than I do). You have to force people to run this script manually, or you go around destroying any existing v2.0 databases (which at this point. should only be on development and test machines anyway). This is not a great option, but if you are not deep into 2.0 it is sometimes viable.
Option #2 is a bit friendlier. The v1.0 databases will pick up the fix from 01.00.0046. The v2.0 databases will pick up the fix from 02.00.0003. You have to be careful though, to write the 02.00.0003 change script so that it won't try to reapply changes if the 01.00.0046 script ran.
In other words, databases installed from the v2.0 baseline script need to apply the 02.00.0003 script, but production type databases that have been around since 1.0 will use the 01.00.0046 script, and you don't want 02.00.0003 to create an error by making changes that are already in place when the database eventually updated to v2.0.
Whew, I hope all that makes sense. Branches and schema changes always make me nervous, but fortunately, they are rare. Even when they do occur, the change scripts usually involve simple changes and not the kind of big changes you see in a script written during feature development.
Questions
In a previous post, Jason asked:
#1: I generally only baseline between releases. This means new installs might have to run a heap of update scripts, but since they are new installs and the process is automated – it's not a big deal. The benefit is I don't have to keep baseline scripts synchronized, which is one less chore to perform when updating the schema. When creating a baseline, it's easy to use a SQL diff tool to make sure the baseline is identical to a database created by running the previous baseline plus all the update scripts.
#2: The change scripts many tools build often don't work for me because of the size of the databases I work with. Some of these scripts will run for hours and hours. Most of the change scripts are hand written with loving care. It's great to have a few developers around who are good with SQL – I know not every team has this luxury, and I honestly don't have a good answer to that problem.
I Think It's Over ... For Now
I've glossed over many details, but I think this is all I have to say on the matter of database versioning for now. Hopefully, these short blog posts made some sense.
The goal of versioning a database is to push out changes in a consistent, controlled manner and to build reproducible software. Since the change scripts are all version controlled and labeled with build numbers, you can create any past version of the database that you need.
My goal in writing these posts was to get people who don't version control their database to think about starting. If you already version control your database, I hope these posts have validated your thinking, or given you ideas. It could be that you already have a much better process in place, in which case you should try to blog about your process, because there is a dearth of information on the Internet about this topic. Better yet – write an article or a book, but hurry up, we need to hear from you!
What started as a short brain dump is tuning in to a longer series of posts thanks to all the feedback and questions. In this post, I want to explain some of my thoughts on controlling objects like database views, stored procedures, functions, and triggers.
But first...
I haven't actually used a trigger in years. This isn't to say that triggers aren't valuable, but I've tended to shy away. Jon Galloway has posted a good example of what you can do with triggers.
Secondly, stored procedures have fallen out of favor in my eyes. I came from the WinDNA school of indoctrination that said stored procedures should be used all the time. Today, I see stored procedures as an API layer for the database. This is good if you need an API layer at the database level, but I see lots of applications incurring the overhead of creating and maintaining an extra API layer they don't need. In those applications stored procedures are more of a burden than a benefit.
One File per Object
My strategy is to script every view, stored procedure, and function into a separate file, then commit the files to source control. If someone needs to add a new view, they script the view into a file and commit the file to source control. If someone needs to modify a view, they modify the view's script file and commit again. If you need to delete a view from the database, delete the file from source control. It's a relatively simple workflow.
The magic happens when a developer, tester, or installer updates from source control and runs a tool that updates their local database. The tool uses a three step process:
Say What?
People often wonder why I want to drop and destroy all these objects and then re-add them. You could lose work if you update your database and haven't scripted out a view you were in the middle of creating.
The simple reason is to find problems as early as possible. If someone commits a schema change and the change removes a column used by a view, you'll find out there is an error early – hopefully before the build escapes for testing. Likewise, if someone checks in a view but forgets to publish a schema change the view needs, someone else is going to show up at their desk a few minutes later asking why they are breaking the software.
A second reason is to avoid some rare errors I've seen. Some databases have a tendency to screw up execution plans when the schema changes underneath a view. Dropping everything and starting over avoids this problem, which is really hard to track down.
Of course, this does mean a database will need a little down time to apply updates. I realize not everybody has that luxury.
Summary
Through the power of source control and automation, every database from development to production can keep a schema in synch. If you need to go back in time to see what the database looked like on July 20, 2007, or in build 1.58 of the application, you can do that with this strategy, too.
Next question: what happens if there is a branch in the source control tree? That's a topic for the next post.
After considering the three rules and creating a baseline, an entire team can work with a database whose definition lives safely in a source control repository. The day will come, however, when the team needs to change the schema. Each change creates a new version of the database. In my plan, the baseline scripts created a schema change log to track these changes.

By "change", I mean a change to a table, index, key, constraint, or any other object that requires DDL, with the exception of views, stored procedures, and functions. I treat those objects differently and we'll cover those in the next post. I also include any changes to static data and bootstrap data in change scripts.
Alternatives
Before jumping into an example, I just wanted to point out there are many ways to manage database changes and migrations. Phil Haack describes his idempotent scripts in Bulletproof Sql Change Scripts Using INFORMATION_VIEWS. Elliot Smith and Rob Nichols are database agnostic with Ruby Migrations. If you know of other good articles, please post links in the comments. Again, the goal is to manage change in the simplest manner possible for your project.
Example, Please
The team just baselined their database that includes a Customers table, but now wants to add a new column to store a Customer's shoe size. They also realized their OrderState table, a lookup table that include the values 'Open', and 'Shipped', now needs a new value of 'Canceled'. They would need to create a schema change script that looks like the following. Notice I can include as many changes as needed into a single script.
File: sc.01.00.0001.sql
Whoever writes this change script will test it thoroughly and against a variety of test data, then commit the change script into source control. The schema change is officially published. The schema change will start to appear in developer workspaces as they update from source control, and on test machines as new builds are pushed into QA and beyond.
It's good to automate database updates as ruthlessly as possible. Ideally, a developer, tester, or installer can run a tool that looks at the schema version of the database in the SchemaChangeLog table, and compares that version to the available updates it finds in the form of schema change scripts that reside on the file system. Sorting files by name will suffice using the techniques explained here. Command line tools work the best, because you can use them in build scripts, developer machines, and install packages. You can always wrap the tool in a GUI to make it easy to use. Here's the output I recently saw from a schema update tool (some entries removed for brevity):
Connected to server .
Connected to database xyz
Host: SALLEN2 User: xyz\sallen
Microsoft SQL Server 2005 - 9.00.3054.00 (Intel X86)
Schema history:
05.00.0000 initial-install on Dec 13 2007 11:26AM
05.00.0001 sc.05.00.0001.sql on Dec 13 2007 11:26AM
05.00.0002 sc.05.00.0002.sql on Dec 13 2007 11:26AM
...
05.00.0012 sc.05.00.0012.sql on Dec 13 2007 11:26AM
05.01.0000 sc.05.01.0000.sql on Dec 13 2007 11:26AM
05.01.0001 sc.05.01.0001.sql on Dec 13 2007 11:26AM
...
05.01.0019 sc.05.01.0019.sql on Dec 13 2007 11:26AM
Current version:
05.01.0019
The following updates are available:
sc.05.01.0020.sql
sc.05.01.0021.sql
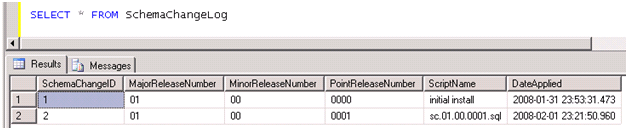
Once a developer runs the schema change in this post, they should see the following in the schema change log:
Schema Change Rules and Tips
Once a script is published into source control, it cannot be changed! Once someone updates their database with an update script, they should never have to run the same script on that same database.
The responsibility of updating the SchemaChangeLog table should reside with the tool that applies the updates. This way, the tool can ensure the script runs to completion before the recording the update into the change log.
Always backup a production database before applying a change script. If a change script happens to fail with an error, you can at least get the database back into a known state.
Some people will wonder what happens if multiple developers are all working on change scripts at the same time. Fortunately, the source control repository is a great mediator. I can't add an update script with the same name as your update script – I'll have to rev my version number if you beat me to the commit by a few seconds.
Of course, changes are not just about schema changes. You also have to write the code to migrate data. For instance, if for some reason we moved the ShoeSize column from the Customers table to the CustomerDetails table, the update script will also need to move and preserve the data. Data manipulation is often the trickiest part of change scripts and where they need the most testing.
Summary
Managing change with your database yields a great many benefits. Since the schema change scripts are in source control, you can recreate your database as it looked at any point in time. Is a customer reporting a bug on build 3.1.5.6723? Pull the source code tagged or labeled with that version number and run the baseline, then all schema change scripts included in the tag. You now have the same database and have a much better chance to recreate the bug. Also, changes move from development to test, and ultimately into production in a consistent, orderly, and reproducible manner.
I've skipped over quite a few nitty-gritty details, but I hope you get the general idea. I've used this approach for years and its worked well. Still, I feel the approach is a bit long in the tooth and I'm looking for ways to improve. Feedback is appreciated. What do you think?
Coming up next – managing views and stored procedures.
Continuing from the last post (Three Rules for Database Work), I wanted to drill into some database versioning strategies that have worked well for me.
Caveats and Considerations
As a preface, let me say there are many different strategies that can work. I'm not presenting the one true way. My goal is to roll out database changes in a consistent, testable, reproducible manner. I'm used to working with largish databases that are packaged to install behind a customer's firewall. I don't want to use naïve update scripts that run for 6 hours. Concerns like this bias my thinking and strategies. Every application should manage database change, but you'll have to decide on the simplest strategy that works for your environment.
The Baseline
The first step in versioning a database is to generate a baseline schema. This is the starting point for versioning a database. After you've published the baseline to an authoritative source, any changes to the schema require a schema change script (a topic for the next post, because I have a feeling this is going to be long for a blog post).
You are probably not going to baseline the database on day 1 of a project. I'd suggest letting the early design of the schema settle in a bit so you are not creating a huge number of change scripts. This might sound like I'm suggesting you need to do some big, up front schema design – but that's not true. You can get pretty far into an application these days with in-memory data, fakes, stubs, mocks, and unit tests. Once the model in your code starts to stabilize, you can start thinking of the schema required to persist all the data. If you are ORMing, you can even generate the first schema from your model.
On the other hand, maybe your project and database have already been around a couple years. That's ok – you can baseline today (tomorrow at the latest), and manage change moving forward.
But How?
If you want to do things the hard way, then open a new file in a text editor and write all the SQL commands that will create every table, constraint, function, view, index, and every other object in your database. You'll also want to include commands that populate lookup tables with static data and include any bootstrap data needed by the application. Test the new script against a fresh database server and if successful, commit the file to source control. Consider your schema baselined!
Nobody really does this step the hard way, though. Most of us use tools that we point to a database, and the tools generate one or more scripts for us. Some people like to generate everything into one big script file. Others like to generate one script file for every database object. SQL Server Management Studio provides both option when you elect to script a database. I've seen both approaches work, but the "one file per object" approach feels cumbersome on a day to day basis, and unwieldy if the number of objects grow into the thousands.
Personally, I like to take a hybrid approach. I like to keep all of the SQL needed to create tables, constraints, defaults, and primary indexes in a single file. Any views, stored procedures, and functions are scripted one per file.
If you go the multiple file approach, make sure to write a batch file, shell script, application, or some other form of automation that can automatically locate and run all of the script files required to install the database. Human intervention in this process is a step backwards.
Also, many tools like to include CREATE DATABASE commands and/or include database names in the scripts they generate. You'll want to purge any reference to a hardcoded database name. You want the name to be configurable (a default name is fine), and you probably want to support multiple databases for your application on the same database instance (mostly for testing).
Whichever approach you take (one single file, or multiple files), you now have scripts that can recreate the database schema on any developer machine, test machine, or production machine. Everyone uses the exact same schema. Congratulations! You've just increased the quality of your software because the database can be reliably reproduced in any environment.
I Almost Forgot the Most Important Ingredient
At some point in the future, the schema will have to change. Before you baseline the database you need to add a table to record these schema changes. The following table is the kind of table I'd use to track every change to a database.
The first baseline schema script should, as the last step, officially install version 1.0 of the database:

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#