
In Part I, we defined an IUnitOfWork interface to avoid coding directly to the System.Data.Linq.DataContext class. IUnitOfWork gives us the opportunity to manipulate IDataSource<T> objects.
IDataSource<T> is another abstraction. When the software is running in earnest, we need to back an IDataSource<T> with a table in a SQL Server database. However, during unit testing we might prefer to have an IDataSource<T> backed by an in-memory data structure. Essentially, we want the ability to switch between a System.Data.Linq.Table<T> implementation (SQL Server) and a System.Collections.Generic.List<T> implementation (in-memory) - without changing the code and LINQ expressions in the upper layers of software.
Fortunately, a handful of interfaces define every Table<T> object. If we implement the same interfaces, we can walk and talk just like a real Table<T>.
Implementing a persistent data source, one that talks to SQL Server, is as simple as forwarding the calls to an underlying Table<T> implementation.
Implementing an in-memory data source is a little bit trickier, but appears possible thanks to extension methods like AsQueryable on the System.Linq.Queryable class.
Of course, this naïve implementation could never support the full application, but should be suitable for the majority of isolated unit tests.
In the next post, we'll tie everything together to see how all these abstractions work together.
In the meantime, read Rick Strahl's "Dynamic Expression in LINQ to SQL". It is scenarios like the ones that Rick is presenting that make me worry that this approach will fall apart when it hits real requirements.
We interrupt this LINQ series with an emergency!
Well, there is no real emergency, but there hasn’t been a WWWTC for some time, so …
The following program is suppose to compress its own source code into a Program.cs.zip file, then reverse the compression and produce a Program.txt file.
The problem is: Program.txt always shows up as an empty file!
What’s wrong?
Hint: You can fix the program by adding a single line of code.
In June, Ian Cooper wrote an article (Being Ignorant With LINQ to SQL) that provided marvelous details about using POCOs with persistence ignorant repositories. Ian's conclusion: "LINQ to SQL is usable with a TDD/DDD approach to development. Indeed the ability to swap between LINQ to Objects and LINQ to SQL promises to make much more of the code easily testable via unit tests than before."
I've been tinkering along the same lines as Ian, and although I think I started working at the other end of the problem first, I'm reaching the same conclusions (and ended up with much of the same code).
I started working with a trivial case, thinking if the trivial case becomes difficult, the topic isn't worth pursuing. Let's suppose we have the following class.
The idea is that each FoodFact object will ultimately be persisted as a row in a SQL Server database, but I don't want to clutter up the FoodFact class with unrelated attribute decorations or other database nonsense. To get into the database, I do need some sort of gateway, or class that can track POCO objects and determine if they need persisted. In LINQ, this class is the System.Data.Linq.DataContext class. The DataContext class itself doesn't implement any interesting interfaces, so my plan was to abstract the DataContext in a a stubable, fakeable, mockable fashion.
We have not looked at IDataSource yet, but there will be at least two implementations of IUnitOfWork. One implementation will work against a real database using a persistent data source (where FoodDB is a class derived from DataContext):
Another implementation will work with an "in memory data source". This class would be defined in a unit test project.
The goal is to consume IUnitOfWork along these lines:
What are these data sources? Stay tuned for part II ...
Here is one I had to track down recently.
The code in the following activity is trivial, but FaultyActivity represents any activity that might throw an exception during Execute and overrides HandleFault (which the WF runtime will schedule to run when it catches the exception tossed up by Execute).
The problem is that once an activity enters the Faulting state, it can only transition to Closed or back to Faulting. If another exception escapes during fault handling, the activity transitions back into the Faulting state, and WF schedules HandleFault to execute again - it’s an infinite loop if the exception continues to occur.
Adding some tracing to the app config file..
.. confirms the problem (abridged version):
Activity Status Change - Activity: faultyActivity1 Old:Initialized; New:Executing
Scheduling entry: ActivityOperation((1)faultyActivity1, Execute)
Execute of Activity faultyActivity1 threw System.InvalidOperationException
Activity Status Change - Activity: faultyActivity1 Old:Executing; New:Faulting
Scheduling entry: ActivityOperation((1)faultyActivity1, HandleFault)
Compensate of Activity faultyActivity1 threw System.InvalidOperationException
Activity Status Change - Activity: faultyActivity1 Old:Faulting; New:Faulting
Scheduling entry: ActivityOperation((1)faultyActivity1, HandleFault)
Compensate of Activity faultyActivity1 threw System.InvalidOperationException
Activity Status Change - Activity: faultyActivity1 Old:Faulting; New:Faulting
Scheduling entry: ActivityOperation((1)faultyActivity1, HandleFault)
Compensate of Activity faultyActivity1 threw System.InvalidOperationException ...
The sinister aspect to this behavior is that if enough workflows get into the infinite faulting loop, the threadpool becomes starved and the entire application just sits and spins with no work getting done.
Moral of the story – never let an exception escape from HandleFault.
Anytime you open up a design tool, and see something like this ...
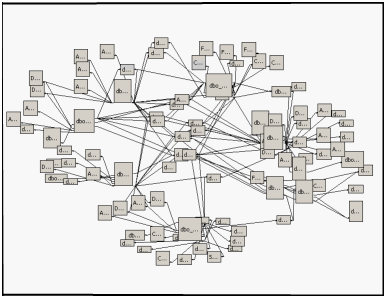
... you know you'll need stiff drink at the end of the day. It doesn't matter if the boxes represent tables or classes – it's a complicated mess. In this case, the screenshot is from a Visual Studio 2005 Analysis Services project.
Anyone have some aspirin to spare?
Water . When you don't have it - you can find out who your true friends are. Your true friends are the ones who open the door when you are standing outside with a towel, toothbrush, razor, and clean pair of underwear in hand.
Last week I turned the tap at the kitchen sink and .... nothing happened. Plumbing is far beyond my area of expertise, so I called for professional help. The plumber poked around and decided everything from the well pump to the kitchen tap was in perfect working order. Like any good debugging session, there was only one possibility left – not enough water left in the well.
There are about 20 million people in the United States drawing water from private wells. These wells can go dry for a number of reasons. A lack of rain is one reason, but there is also overdraft (removing too much water from the ground) and the mysteries of geological change.
I had three options:
In option 1, I call someone who can pour a truckload of water into the well. This solution is viable when there is a severe drought and the water table has dropped below the well. The standard 15 cm diameter well can hold about 1.5 gallons of water per foot of depth. I'd be hoping that heavy rains can once again raise the water table and the well will begin a natural recovery before exhausting the pumped in water. We've been dry, but it didn't sound like this was a long term solution to my problem.
In option 2, I faced a few unknowns. Nobody can tell me how deep someone will need to drill before reaching an aquifer. Wells in my area can range from 100 feet to 900 feet (30m to 270m) in depth. Since a well driller might charge anywhere from $20 to $40 a foot, there is a lot of variability in the cost.
Option 3 is something I hadn't previously heard of. In fact, when someone suggested "fracking" my well, I took it as a euphemism for "screw it - fuggetaboutit - it's dead". As it turns out, "fracking" means "hydro-fracturing" - a technology adopted from the oil and gas industries. The frackers can give you a set cost ($2k - $4k), and fracking works 97% of the time. Fracking is the option I took. Fracking uses high pressure to clean the rock fissures of sediment and create new fractures in the rock, thus allowing more water into the well.
The fracking took about 4 hours. First, the frackers have to remove the pump, hose, and cables from the well. Next, the frackers lower a packer into the well, and inflate the packer (think of a packer as a heavy-duty balloon). The frackers then fill the area under the packer with potable, chlorinated water and add pressure. Tremendous amounts of pressure – typically 1000 to 3000 psi. The frackers continue to add water and raise the pressure until the pressure drops off and stabilizes. For my well, the drop-off happened at 1500 psi. After that point, there is the reinstallation of the pump and the cleanup.
Water flows once again!
Here are two of the links I found interesting during this process.
Wellowner.org – informing consumers about ground water and water wells.

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#