
I wrote a Visual Studio macro to walk an ASP.NET 2.0 project and create a web.sitemap based on the physical layout of files.
The macro requires a reference to System.Xml.dll. The macro won’t overwrite or synchronize an existing web.sitemap file, it’s only meant to save some typing if you have an existing project and want to add a sitemap. Once the macro creates the sitemap, you can go in and modify the titles, descriptions, and layout.
Update: Fixed the macro to work with IIS based projects, and added Dan Kahler's suggestion to prompt user to overwrite existing file.

When I first heard about Windows Workflow Foundation, I wasn’t particularly excited. “Workflow” has long been a buzzword used by vendors, product managers, and venture capitalists in mind numbing phrases like: “Our workflow solution will leverage your strategic business assets and put you in the fast lane of the information superhighway”.
Yawn.
Nevertheless, I knew some people who were taking Workflow seriously, so I decided to give the preview bits a try. Workflow is a success. The designer works well – both the user interface and the programming interface are intuitive. For a good description of the feature set, which includes state machine workflows and long running workflows, see David Chappell’s “Introducing Windows Workflow Foundation”.
Here is a code activity that Workflow invokes. It would be nice if the Parameters turned into strongly typed properties.
private void Fetch_ExecuteCode(object sender, EventArgs e)
{
FetchSettings settings = new FetchSettings();
settings.ConnectionString = Parameters["ConnectionString"].Value as string;
settings.LocalDataPath = Parameters["LocalDataPath"].Value as string;
// ...
FetchProcessor processor;
processor = new FetchProcessorFactory.GetConfiguredFetchProcessor(settings);
_files = processor.Process();
}
To kick off a workflow...
private void StartImport()
{
if (!workflow.IsStarted)
{
workflow.StartRuntime();
workflow.WorkflowCompleted +=
new EventHandler<WorkflowCompletedEventArgs>
(workflow_WorkflowCompleted);
workflow.WorkflowTerminated +=
new EventHandler<WorkflowTerminatedEventArgs>
(workflow_WorkflowTerminated);
}
Type importType = typeof(ImportWorkflow);
Dictionary<string, object> parameters = new Dictionary<string, object>();
// ...
parameters.Add("LocalDataPath", Path.GetTempPath());
parameters.Add("ConnectionString", Settings.Default.wfStatsConnectionString);
workflow.StartWorkflow(importType, parameters);
}
I like to write about a topic before I give a presentation. Writing is my way of organizing random thoughts into an arbitrary collection of opinions.
When I signed up to do a presentation at the last local code camp, I got behind on writing about membership and role providers in ASP.NET 2.0. I finally finished the writing this weekend (Part I, Part II).
Miguel Castro also covered membership features at the last code camp. Miguel concentrated on the login controls and UI customization while I stuck more to the configuration and other details. Miguel knows a great deal about ASP.NET server controls –just listen to his .NET Rocks appearance. Two thumbs up!
The following is an excerpt from PAG’s “How To: Use Role Manager in ASP.NET 2.0”.
You can control access to pages or folders to members of one of the built-in Windows groups by specifying the role in the format BUILTIN\groupName. The following example allows users in the built-in administrators group to view pages in the folder named memberPages and denies access to anyone else.
The problem is, the default authorization rule is:
The ASP.NET module responsible for authorization checks iterates through rules starting with the local web.config file, and ending with the “allow all users” default rule. As soon as the module finds a rule matching the current user, it stops evaluating rules.
The PAG example is only denying access to anonymous users. If a user is authenticated, but not in the Administrator role, they'll still get access by falling through to the allow users="*" rule.
To really keep out non-Administrators, you want to use:
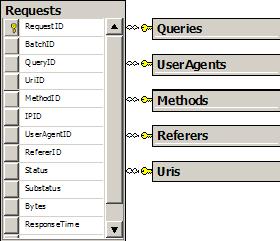
I had a star schema and an XML document of creamy data to stuff inside. What’s the best approach to updating the dimension tables with new values? There are many tried and true approaches to evaluate.
Let’s take the specific case of the Referers table. This table stores a RefererID, and a Referer string. I have an XML document full of Request elements, each with a Referer attribute. I needed to look at each element and find any Referer values that do not exist in the database to insert only new values.
<Request Date="2005-11-15T07:59:59Z"
Uri="/Articles/rss.aspx"
Referer=""
Status="200"
ResponseTime="609"
/>
One approach would be to parse the file, lookup each referrer in the database, and execute an INSERT statement if the value isn’t found. This approach uses at least two database roundtrips per request, so processing a large number of records will crawl.
Another approach is to pass the entire document to SQL Server 2005 and work with the new XML capabilities.
CREATE PROCEDURE [Stats].[ImportReferers]
@WebStatistics AS XML
AS
BEGIN
SET NOCOUNT ON;
WITH XMLNAMESPACES(DEFAULT 'https://odetocode.com/wfStatsImport.xsd')
INSERT INTO Stats.Referers
SELECT DISTINCT request.value('@Referer', 'varchar(900)')
FROM @WebStatistics.nodes('//Request') AS Request(request)
LEFT JOIN Stats.Referers R ON
R.Referer = request.value('@Referer', 'varchar(900)')
WHERE R.Referer IS NULL
END
In SQL 2005 there are at least two approaches to transforming XML into a rowset. Once approach is OPENXML, but the code still gets a messy with pre and post-processing. A cleaner approach is to take advantage of the native XML data type in 2005, which offers query(), value(), exist(), modify() and nodes() methods. The nodes() method is just what I needed to transform XML elements into a relational table. The value() method can pull out an attribute to act like a column. All I needed then was a LEFT JOIN to find just the Referer values that didn’t already exist. Performance has been acceptable for a server running on Virtual PC.
Once the web log files were downloaded and unzipped, I transformed them into an XML document and looked for a way to get the records into SQL Server. My first thought was to learn more about SQL Server Integration Services, the successor to DTS.

I’ve used DTS in the past to fast-load millions of records into data marts. Although the performance numbers were excellent, I’ve always held misgivings about DTS because the packages were opaque, and difficult to maintain and use in generic solutions.
Although I made a fair amount of progress with SSIS, I ultimately ditched the approach for the following reasons:
I wanted to like SSIS. SSIS has made vast improvements over DTS. The packages are now XML files, meaning you can look at them, diff them, and check them into source control as text. There are more tasks available, and you can plug-in your own code.
The biggest obstacle was the Script Task would not let me design a script. The reason I wanted to execute a Script Task was to find an elegant solution to inserting a parent record, retrieving an identity value, and inserting child records with the identity as an FKEY. This common task seems to require an inordinate amount of work in SSIS.
In 1.1 we needed third party libraries to compress and uncompress data. In .NET 2.0 we have GZipStream and DeflateStream classes. However, as Stephen Toub points out in .NET matters, these classes are don’t handle the headers, footers, and other metadata of popular archive formats like gzip and zip.
In looking for the simplest possible solution to unzipping a single file in a windows forms application, I decided to interop with Shell32.dll. The disadvantage appears to be the inability to perform a “silent” operation – the shell always displays a modeless progress dialog no matter what flags are passed to the CopyHere method. I tried to do some native interop debugging to figure out if the flags parameters was somehow getting munged in the interop boundary, but gave up. Part of my frustration was the disappearance of the Registers and Modules windows in the Visual Studio menus. I had to look up the shortcut keys to get to these commands. Apparently, this is a “feature” of the 2005 IDE that Paul Litwin also ran into.
The advantage to using Shell32 is the small amount of code required.
public class UnzipLogFileTransformer : ITransformer
{
public string TransformFile(string inputFileName)
{
Check.IsRootedFileName(inputFileName, "inputFileName");
string destinationPath = Path.GetDirectoryName(inputFileName);
string outputFileName = Unzip(inputFileName, destinationPath);
File.Delete(inputFileName);
return Path.Combine(destinationPath, outputFileName);
}
private string Unzip(string inputFileName, string destinationPath)
{
Shell shell = new ShellClass();
Folder sourceFolder = shell.NameSpace(inputFileName);
Folder destinationFolder = shell.NameSpace(destinationPath);
Check.IsTrue(sourceFolder.Items().Count == 1,
"Archive should contain only 1 item");
string outputFileName = sourceFolder.Items().Item(0).Name;
Check.IsNotNullOrEmpty(outputFileName, "outputFileName");
destinationFolder.CopyHere(sourceFolder.Items(),
OpFlags.TotallySilent);
return outputFileName;
}
}

 OdeToCode by K. Scott Allen
OdeToCode by K. Scott Allen
 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#