
In the first part of this series we talked about resources, but mostly focused on URLs and how to interpret a URL. However, resources are the centerpiece of HTTP. Now that we understand HTTP messages, methods, and connections we can return to look at resources in a new light. In this article we'll talk about the true essence of working with resources when architecting web applications and web services.
The Series:
Part I: ResourcesPart II: Messages
Part III: Connections
Part IV: Architecture (you are here)
Part V: Security
Resources Redux
Although it is easy to think of a web resource as a file on a web server's file system, thinking along these lines disrespects the true capability of the resource abstraction. Many web pages do require physical resources on a file system – JavaScript files, images, and style sheets. However, consumers and users of the web don't care much for these background resources. Instead, they care about resources they can interact with, and more importantly resources they can name. Resources like:
- the recipe for broccoli salad
- the search results for "Chicago pizza"
- patient 123's medical history
All of these resources are the types of resources we build applications around, and the common theme in the list is how each item is significant enough to identify and name. If we can identify a resource, we can also give the resource a URL for someone to locate the resource. A URL is a handy thing to have around. Given a URL you can locate a resource, of course, but you can also hand the URL to someone else by embedding the URL in a hyperlink or sending it in an email.
But, there are many things that you can't do with a URL, or rather, there are many things a URL cannot do. For example, a URL cannot restrict the client or server to a specific type of technology. Everyone speaks HTTP. It doesn't matter if your client is C++ and your web application is in Ruby.
Also, a URL cannot force the server to store the resource using any particular technology. The resource could be a document on the file system, but a web framework could also respond to the request for the resource and build the resource using information stored in files, stored in databases, retrieved from web services, or simply derive the resource from the current time of day.
A URL can't even specify the representation of a specific resource, and a resource can have multiple representations. As we learned in part I and witnessed in part II, a client can request a particular representation using headers in the HTTP request message. A client can request a specific language, or a specific content type. If you ever worked with a web application that allows for content negotiation, you've seen the flexibility of resources in action. JavaScript can request patient 123's data in JSON format, C# can request the same resource in XML format, and a browser can request the data in HTML format. Three different representations of a single resource.
There is one more thing a URL cannot do – it cannot say what a user wants to do with a resource. A URL doesn't say if I want to retrieve a resource or edit a resource. It's the job of the HTTP request message to describe the intention of the user using one of the HTTP standard methods. As we talked about in part II, there are a limited number of standard HTTP methods, including GET, POST, PUT, and DELETE.
When you start thinking about resources and URLs as we are in this article, you start to see the web as part of your application and as a flexible architectural layer you can build on. For more insight into this line of thinking, see Roy Fielding's famous dissertation titled "Architectural Styles and the Design of Network-based Software Architectures". The dissertation is the paper that introduces the "representational state transfer" (REST) style of architecture and goes into greater detail about the ideas and concepts in this section and the next.
The Visible Protocol - HTTP
So far we've been focused on what a URL can't do, when we should be focused on what a URL can do. Or rather, focus on what a URL + HTTP can do, because they work beautifully together. In his dissertation, Fielding describes the benefits of embracing HTTP. These benefits include scalability, simplicity, reliability, and loose coupling. HTTP offers these benefits in part because you can think of a URL as a pointer, or a unit of indirection, between a client and server application. Again, the URL itself doesn’t dictate a specific resource representation, technology implementation, or the client’s intention. Instead, a client can express the desired intention and representation in an HTTP message.
An HTTP message is, as we’ve seen, a simple plain text message. The beauty of the HTTP message is how both the request and the response are fully self-describing. A request includes the HTTP method (what the client wants to do), the path to the resource, and additional headers providing information about the desired representation. A response includes a status code to indicate the result of the transaction, but also includes headers with cache instructions, the content type of the resource, the length of the resource, and possibly other valuable metadata.
Because all of the information required for a transaction is contained in the messages, and because the information is visible and easy to parse, HTTP applications can rely on a number of services that provide value as a message moves between the client application and the server application.
Adding Value
As an HTTP message moves from the memory space of a process on one machine to the memory space of a process on another machine, it can move through several pieces of software and hardware that inspect and possible modify the message. One good example is the web server application itself. A web server like Apache or IIS will be one of the first recipients of an incoming HTTP request on a server machine, and as a web server it can route the message to the proper application. The web server can use information in the message, like the host header, when deciding on which application needs to receive the message. But, the server can also perform additional actions with the message, like logging the message to a local file. The applications on the server don’t need to worry about logging because the server is configured to log all messages.
Likewise, when an application creates an HTTP response message, the server has a chance to interact with the message on the way out. Again, this could be a simple logging operation, but it could also be a direct modification of the message itself. For example, a server can know if a client supports gzip compression, because a client can advertise this fact through an accept-encoding header in the HTTP request. Compression allows a server to take a 100kb resource and turn it into a 25kb resource for faster transmission. You can configure many web servers to automatically use compression for certain content types (typically text types), and this happens without the application itself worrying about compression. Compression is an added value provided by the web server software.
Applications don’t have to worry about logging HTTP transactions or compression, and this is all thanks to the self descriptive HTTP messages that allow other pieces of infrastructure to process and transform messages. This type of processing can happen as the message moves across the network, too.
Proxies
A proxy server is a server that sits between a client and server. A proxy is mostly transparent to end-users, so you think you are sending HTTP request messages directly to a server, but the messages are actually going to a proxy. The proxy accepts HTTP request messages from a client and forwards the messages to the desired server. The proxy then takes the server response and forwards the response back to the client. Before forwarding these messages, the proxy can inspect the messages and potentially take some additional actions.
For example, one of the clients I work for uses a proxy to capture all HTTP traffic leaving the office. They don’t want employees and contractors spending all their time on Twitter and Facebook, so HTTP requests to those servers will never reach their destination and there is no tweeting for Farmville inside the office. This is an example of one popular role for proxy servers, which is to function as an access control device. However, a proxy server can be much more sophisticated then just dropping messages to specific hosts – a simple firewall could perform that duty. A proxy server could also inspect messages to remove confidential data, like the referer headers that point to internal resources on the company network. An access control proxy can also log HTTP messages to create audit trails on all traffic. Many access control proxies require user authentication, a topic we’ll look at in the next article.
The proxy I’m describing in the beginning of the above paragraph is generally thought of as a forward proxy. Forward proxies usually are closer on the network to the client than the server, and forward proxies usually require some configuration in the client software or web browser to work. A reverse proxy is a proxy server that is closer to the server than the client, and is completely transparent to the client. Both types of proxies can provide a wide range of services. For example, if we return to the gzip compression scenario we talked about earlier, a proxy server has the capability to compress response message bodies. A company might use a proxy server for compression to take some of the load off the server where the application lives. Now, neither the application or the web server has to worry about compression. Instead, compression is a feature that is layered in via a proxy. That’s the beauty of HTTP.
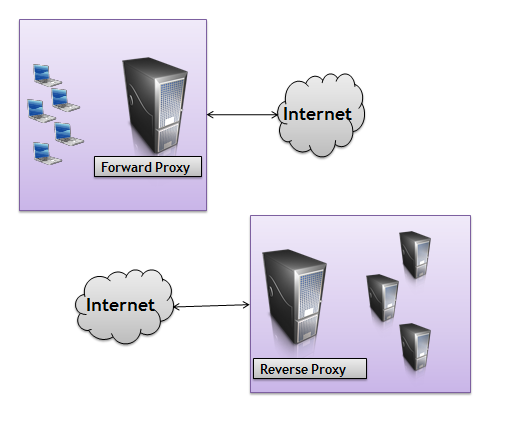
Proxies can perform a wide range of one or more services. The following paragraphs highlight a few of the popular services.
Load balancing proxies can take a message and forward it to one of several web servers on a round-robin basis, or by knowing which server is currently processing the fewest number of requests.
SSL acceleration proxies can encrypt and decrypt HTTP messages, taking the encryption load off a web server. We’ll talk more about SSL in the next article.
Proxies can provide an additional layer of security by filtering out potentially dangerous HTTP messages. Specifically, messages that look like they might be trying to find a cross-site scripting (XSS) vulnerability or launch a SQL injection attack.
Caching proxies will store copies of frequently access resources and responding to messages requesting those resources directly. We’ll go into more detail about caching in the next section.
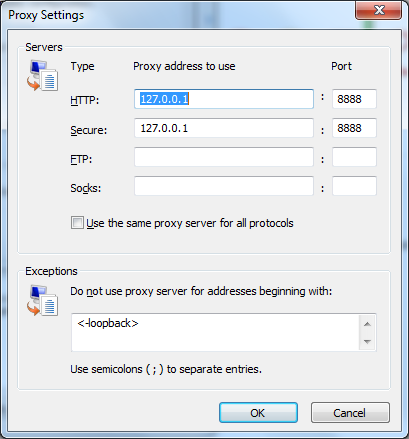
Finally, it is worth pointing out that a proxy doesn’t have to be a physical server. Fiddler, a tool mentioned in a previous article, is an HTTP debugger that allows you to capture and inspect HTTP messages. Fiddler works by telling Windows to forward all outgoing HTTP traffic to port 8888 on IP address 127.0.0.1. This IP address the loopback address, meaning the traffic simply goes directly to the local machine where Fiddler is now listening on port 8888. Fiddler takes the HTTP request message, logs it, forwards it to the destination, and also captures the response before forwarding the response to the local application. You can view the proxy settings in Internet Explorer by going to Tools –> Internet Options, clicking on the Connections tab, and then clicking the LAN Settings button. Under the Proxy Server area, click on the Advanced button to see proxy server details.
Proxies are a perfect example of how HTTP can influence the architecture of a web application or web site. There are many services you can layer into the network without impacting the application. The one service we want to examine in more detail is caching.
Caching
Caching is a optimization to improve performance and scalability. When there are multiple requests for the same resource representation, a server can send the same bytes over the network time and time again for each request. Or, a proxy server or a client can cache the representation locally and reduce the amount of time and bandwidth required for a full retrieval. Caching can reduce latency, help prevent bottlenecks, and allow a web application to survive when every user shows up at once to buy the newest product or see the latest press release. Caching is also a great example of how the metadata in the HTTP message headers facilitates additional layers and services.
The first thing to know is that there are two types of caches.
A public cache is cache shared among multiple users. A public cache generally resides on a proxy server. A public cache on a forward proxy is generally caching the resources that are popular in a community of users, like the users of a specific company, or the users of a specific Internet service provider. A public cache on a reverse proxy is generally caching the resources that are popular on a specific web site, like popular product images from Amazon.com.
A private cache is dedicated to a single user. Web browsers always keep a private cache of resources on your disk (these are the “Temporary Internet Files” in Internet Explorer, or type about:cache in the address bar of Google Chrome to see files in its private cache). Anything a browser has cached on the file system can appear almost instantly on the screen.
The rules about what to cache, when to cache, and when to invalidate (or kick an item out of the cache) are unfortunately complicated and mired by some legacy behaviors and incompatible implementations. Nevertheless, I will endeavor to point out some of the things you should know about caching.
In HTTP 1.1, a response message with a 200 (OK) status code for an HTTP GET request is cacheable by default (meaning it is legal for proxies and clients to cache the response). An application can influence this default by using the proper headers in an HTTP response. In HTTP 1.1 this header is the Cache-control header, although you can also see an Expires header in many messages, too. The Expires header is still around and is widely supported despite being deprecated in HTTP 1.1. Pragma is another example of a header used to control caching behavior, but it too is really only around for backward compatibility. In this article I’ll focus on Cache-control.
An HTTP response can have a value for Cache-control of public, private, or no-cache. A value of public means public proxy servers can cache the response, a value of private means only the browser can cache the response, and a value of no-cache cache means nobody should cache the response. There is also a no-store value, meaning the message might contain sensitive information and should not be persisted and should be removed from memory as soon as possible. How do you use this information? For popular requests for shared resources (like the home page logo image), you might want to use a public cache control directive to allow everyone to cache the image, even proxy servers. For requests to a specific user (like the HTML for the home page that includes the user’s name), you’d want to use a private cache directive. Note: in ASP.NET you can control these settings via Response.Cache.
A server can also specify a max-age value in the Cache-control. The max-age value is the number of seconds to cache the response. Once those seconds expire, the request should always go back to the server to retrieve an updated response. Let’s look at some sample responses.
Here is a partial response from Flickr.com for one of the flickr CSS files.
HTTP/1.1 200 OK Last-Modified: Wed, 25 Jan 2012 17:55:15 GMT Expires: Sat, 22 Jan 2022 17:55:15 GMT Cache-Control: max-age=315360000,public
Notice the cache control allow public and privates caches to cache the file, and they can keep it around for over 315 million seconds, or 10 years. They also use an Expires header to give a specific date of expiration. If a client is HTTP 1.1 compliant and understands Cache-Control, it should use the value in max-age instead of Expires. Note that this doesn't mean Flickr plans on using the same CSS file for 10 years. When they change their design, they’ll probably just use a different URL for their updated CSS file.
Notice the response also includes a Last-Modified header to indicate when the representation was last changed (which can just be the time of the request). Caches can use this value as a validator, or a value the client can use to see if the cached representation is still valid. For example, if the agent decides it need to check on the resource it can issue the following request.
GET http://… HTTP/1.1 If-Modified-Since: Wed, 25 Jan 2012 17:55:15 GMT
The If-Modified-Since header is telling the server the client only needs the full response if the resource has changed. If the resource hasn’t changed, the server can respond with a 304 – Not Modified message.
HTTP/1.1 304 Not Modified Expires: Sat, 22 Jan 2022 17:16:19 GMT Cache-Control: max-age=315360000,public
The server is telling the client – go ahead and use the bytes you already have cached.
Another validator you’ll commonly see if the ETag.
HTTP/1.1 200 OK Server: Apache Last-Modified: Fri, 06 Jan 2012 18:08:20 GMT ETag: "8e5bcd-59f-4b5dfef104d00" Content-Type: text/xml Vary: Accept-Encoding Content-Encoding: gzip Content-Length: 437
The ETag is an opaque identifier (a value that doesn’t have any inherent meaning), and is typically computed using a hashing function. If the resource every changes, the server will compute a new ETag. A cache entry can be validated by comparing two ETags – if the ETags are the same, nothing has changed. If the ETags are different, it’s time to invalidate the cache.
Where Are We?
In this article we covered some architectural theory as well as practical benefits of HTTP architecture. The ability to layer caching and other services between a server and client has been a driving force behind the success of HTTP and the web. The visibility of the self-describing HTTP messages and indirection provided by URLs makes it all possible. In the next article we’ll talk about a few of the subjects we’ve skirted around, topics like authentication and encryption.


 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#