
 If you enjoyed this article, you'll enjoy the book even more! Order now from Packt Publishing and save 10%!
If you enjoyed this article, you'll enjoy the book even more! Order now from Packt Publishing and save 10%!
Windows Workflow is a runtime and not an application. A host process must load and launch the workflow runtime before starting a workflow. The host process tells the runtime the types of workflows to create, and the runtime manages the lifecycle of the workflows and notifies the host process about important lifecycle events, like workflow completion and termination. The runtime isn't particular about the type of host it lives inside. The host process could be a smart client application running on an office desktop machine, or an ASP.NET worker process running on a server in the rack of a data center.
A host can also customize the workflow runtime by layering additional services on top of the runtime's base feature set. These services can provide persistence support for long-running workflows, tracking support for monitoring workflow execution, and more. One concrete example is the ExternalDataExchangeService we've used in previous articles. We added this service to the runtime when we needed communication between a workflow and its host process. Not all applications will require this feature, so the service is an optional component we add as needed.
In this article, we are going to take a closer look at the Windows Workflow runtime and its available services. We'll start with the WorkflowRuntime class, and then cover the scheduling, tracking, persistence, and transactional services.
The Workflow Runtime
We've used the runtime in previous articles, but let's review what we've learned so far. The WorkflowRuntime class is the host's gateway to Windows Workflow. A host creates an instance of the class, and then subscribes to one or more of the events in the table below. These events report state changes for all workflow instances that the runtime is executing.
| Name | Occurs |
| WorkflowAborted | When an instance aborts |
| WorkflowCompleted | When the instance completes |
| WorkflowCreated | When a successful call to CreateWorkflow completes |
| WorkflowIdled | When a workflow enters an idle state |
| WorkflowLoaded | When a persistence service restores a workflow instance |
| WorkflowPersisted | When a persistence service saves a workflow. |
| WorkflowResumed | When workflow execution continues after a suspension |
| WorkflowStarted | When a workflow firsts starts execution |
The following code demonstrates the general process of creating a runtime, subscribing to events, and then using the runtime to create and run a workflow.
using(AutoResetEvent reset = new AutoResetEvent(false))
{
runtime.WorkflowCompleted += delegate { reset.Set(); };
runtime.WorkflowTerminated += delegate { reset.Set(); };
runtime.StartRuntime();
WorkflowInstance instance;
instance = runtime.CreateWorkflow(typeof(SimpleWorkflow));
instance.Start();
reset.WaitOne();
}
The WorkflowRuntime class provides public methods like CreateWorkflow and StartRuntime to manage the environment and the workflows. These methods can start and stop the runtime, create and retrieve workflows, and add and remove services inside the runtime. We'll be exploring some of these methods in more detail later.
Typically, we wouldn't create a runtime just to execute a single workflow. Most applications will keep the runtime around for the life of the process and run multiple workflows. However, we want to use this simple bit of code to demonstrate configuration and logging features of the WF runtime.
Workflow Runtime Logging
The .NET framework provides a tracing API in the System.Diagnostics namespace. Windows Workflow uses this tracing API to log information about what is happening inside the runtime. Trace information contains more detail than the information provided by the public events of the WorkflowRuntime class. To get to the trace information we first need to enable one or more trace sources in the workflow runtime. Each trace source supplies diagnostic information from a different functional area of Windows Workflow.
When to use tracing
Tracing isn't used during normal operation of an application, but can be invaluable when tracking down performance problems or the cause of an exception. We can't use a debugger to step into the code of the WF runtime, but we can enable logging to see what is happening inside.
There are five trace sources available in WF. We can enable these sources in code, or inside the application's configuration file. The following configuration file will configure all five trace sources.
<configuration>
<system.diagnostics>
<switches>
<add name="System.Workflow.Runtime" value="All" />
<add name="System.Workflow.Runtime.Hosting" value="All" />
<add name="System.Workflow.Runtime.Tracking" value="Critical" />
<add name="System.Workflow.Activities" value="Warning" />
<add name="System.Workflow.Activities.Rules" value="Off" />
<add name="System.Workflow LogToFile" value="1" />
</switches>
</system.diagnostics>
</configuration>
Inside the <switches>section we see the name of each trace source. Each source supplies information from a different area, for examples, when a workflow is evaluating the rules inside a rule set, we will see diagnostic information coming from the System.Workflow.Activities.Rules trace source.
We can configure each trace source with a value indicating the amount of information we need. The available values are All, Critical, Error, Warning, and Information. A value of "All" tells the trace source to give us every available bit of trace information. A value of "Critical" tells the trace source to publish only information about critical errors.
The last entry inside this section (LogToFile) is a trace switch that tells WF to send all trace output to a log file. The log file will have the name of WorkflowTrace.log, and will appear in the working directory of the application. Figure 1 shows the contents of the log file after running our sample code with the above configuration. Each line of output contains the trace source name and a textual message. In this sample, all trace information came from System.Workflow.Runtime source.

When we are inside of the Visual Studio debugger, this trace information will also appear in the Output window. If we want to send logging information to another destination, we can create a new trace listener. We can create trace listeners in the configuration file or in code. A trick for console mode applications is to include trace information in the console output.
console = new TextWriterTraceListener(Console.Out, "console");
Trace.Listeners.Add(console);
using(WorkflowRuntime runtime = new WorkflowRuntime())
using(AutoResetEvent reset = new AutoResetEvent(false))
{
runtime.WorkflowCompleted += delegate { reset.Set(); };
runtime.WorkflowTerminated += delegate { reset.Set(); };
runtime.StartRuntime();
WorkflowInstance instance;
instance = runtime.CreateWorkflow(typeof(SimpleWorkflow));
instance.Start();
reset.WaitOne();
}
We must configure the workflow runtime to send trace information to trace listeners. Placing the following XML inside the <SWITCHES> section will send trace information to all trace listeners.
Diagnostics and tracing aren't the only features of the runtime. We are now going to examine the configuration of services inside the runtime.
Workflow Runtime Configuration
There is an imperative approach to adding services to the runtime, and a declarative approach. The imperative approach creates services in code and adds them to the runtime with the AddService method of the WorkflowRuntime class. The declarative approach configures services using the application's configuration file. We'll see examples of both approaches, but let's look at an introduction to declarative configuration first.
Workflow Configuration Sections
What follows is a skeleton configuration file to initialize the workflow runtime.
<configuration>
<configSections>
<section
name="MyRuntime"
type="System.Workflow.Runtime.Configuration.WorkflowRuntimeSection,
System.Workflow.Runtime, Version=3.0.00000.0,
Culture=neutral, PublicKeyToken=31bf3856ad364e35"/>
</configSections>
<MyRuntime>
<CommonParameters>
<!-- add parameters used by all services -->
</CommonParameters>
<Services>
<!-- add services -->
</Services>
</MyRuntime>
</configuration>
The first important entry is the <configSections> node. This node plugs the section hander for the workflow runtime configuration. In the .NET configuration system, different section handlers manage different sections of the configuration file. WF provides the WorkflowRuntimeSection class to handle its specialized configuration section. In this file, we've assigned the class as a section handler for the <MYRUNTIME>section. When the .NET runtime needs to read <MYRUNTIME>, it will instantiate a WorkflowRuntimeSection to do the work.
The <MyRuntime>section will contain the actual workflow runtime configuration. A workflow configuration section contains two child nodes. The <COMMONPARAMETERS> node will hold name and value pairs that will be available to all the workflow services. If we have multiple services that need the same database connection string, we can add the connection string once inside <COMMONPARAMETERS>instead of copying the string for each individual service. The Services node in this section will contain the service types we add to the workflow runtime.
To have a workflow runtime pick up the correct configuration settings, we need to point the runtime at the right configuration section. We do this by passing the section name as a parameter to the constructor of the WorkflowRuntime class. The code below will initialize the runtime with the configuration settings in the <MYRUNTIME>section.
We can place multiple workflow configuration sections inside of a configuration file. Each section will need a section handler defined where the name attribute of the section handler matches a section name. The type attribute for the section handler is always the fully qualified name of WorkflowRuntimeSection class.
It's possible to start more than one workflow runtime inside an application. We can configure each runtime differently by providing multiple configuration sections. The ability to use multiple runtimes is useful when workflows need different execution environments. We'll see an example in the next section when we take about the workflow scheduling services.
Scheduling Services
Scheduling services in WF are responsible for arranging workflows onto threads for execution. The two scheduling services provided by WF are the DefaultWorkflowSchedulerService and the ManualWorkflowSchedulerService. If we don't explicitly configure a scheduling service, the runtime will use the default scheduler (DefaultWorkflowSchedulerService). Both classes derive from the WorkflowSchedulerService class. We can derive our own class from this base class and override its virtual methods if we need custom scheduling logic.
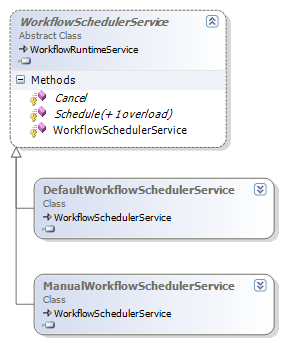
The workflow runtime invokes the Schedule and Cancel methods to plan workflow execution. The default scheduling service will schedule workflows to run on threads from the process-wide CLR thread pool. This is why workflows execute asynchronously on a background thread by default, and why our example waits for the workflow to finish by blocking the main thread with an AutoResetEvent. A host using the manual scheduling service must donate threads to the workflow runtime. The runtime will use a donated thread to execute a workflow. We can use the manual scheduling service to execute workflows synchronously.
Scheduling Services and Threads
Let's take a simple workflow with a single code activity inside. The code activity will invoke the only method in our code behind class, shown below.
{
private void codeActivity1_ExecuteCode(object sender, EventArgs e)
{
Console.WriteLine("Hello from {0}", this.QualifiedName);
Console.WriteLine(" I am running on thread {0}",
Thread.CurrentThread.ManagedThreadId);
}
}
To see the difference between the two scheduling services, we will run the simple workflow once with the manual scheduler, and once with the default scheduler. In this example we are adding the services to the runtime using code.
WorkflowRuntime runtime2 = new WorkflowRuntime();
ManualWorkflowSchedulerService scheduler;
scheduler = new ManualWorkflowSchedulerService();
runtime1.AddService(scheduler);
WorkflowInstance instance;
instance = runtime1.CreateWorkflow(typeof(SimpleWorkflow));
Console.WriteLine("Setting up workflow from thread {0}",
Thread.CurrentThread.ManagedThreadId);
instance.Start();
scheduler.RunWorkflow(instance.InstanceId);
instance = runtime2.CreateWorkflow(typeof(SimpleWorkflow));
instance.Start();
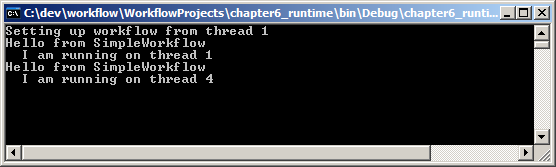
We have two workflow runtimes active in this example. We configure runtime1 to use the manual workflow scheduler. We don't explicitly configure runtime2 with a scheduler, so this runtime will use the default scheduler. Our code prints out the current thread ID before executing any workflows.
Notice how running a workflow with the manual scheduler is a two-step process. First, we must schedule the workflow to run by calling Start on the workflow instance. Calling Start only prepares the runtime for this instance and does not actually run the workflow. To have the workflow execute we explicitly call RunWorkflow on the manual scheduling service and pass an instance ID. The manual service will use the calling thread to execute the workflow synchronously. This is how a host donates a thread.
With the default scheduling service in runtime2, we only need to call Start on our workflow instance. The default scheduler will automatically queue the workflow to run on a thread from the thread pool. We can see the different threads by running the program and observing the output. When using runtime1 the workflow will execute on the same thread as the calling program. When using runtime2 the workflow will execute on a different thread.
Scheduling Services and Configuration
One advantage to configuring our runtimes using the application configuration file is that we can change services and service parameters without recompiling an application. Let's see what our last program might look like if we used the following configuration file.
<configuration>
<configSections>
<section
name="ManualRuntime"
type="System.Workflow.Runtime.Configuration.WorkflowRuntimeSection,
System.Workflow.Runtime, Version=3.0.00000.0,
Culture=neutral, PublicKeyToken=31bf3856ad364e35"/>
<section
name="DefaultRuntime"
type="System.Workflow.Runtime.Configuration.WorkflowRuntimeSection,
System.Workflow.Runtime, Version=3.0.00000.0,
Culture=neutral, PublicKeyToken=31bf3856ad364e35"/>
</configSections>
<ManualRuntime>
<Services>
<add type=
"System.Workflow.Runtime.Hosting.ManualWorkflowSchedulerService,
System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral,
PublicKeyToken=31bf3856ad364e35"
useActiveTimers="true"/>
</Services>
</ManualRuntime>
<DefaultRuntime>
<Services>
<add type=
"System.Workflow.Runtime.Hosting.DefaultWorkflowSchedulerService,
System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral,
PublicKeyToken=31bf3856ad364e35"
maxSimultaneousWorkflows="3" />
</Services>
</DefaultRuntime>
</configuration>
Notice we have two workflow configuration sections with a section handler for each section. The ManualRuntime section configures the manual scheduler and the DefaultRuntime section configures the default scheduler. Each service has an additional configuration parameter. We'll return to discuss these parameters. We must change our code to use this configuration file.
WorkflowRuntime runtime2 = new WorkflowRuntime("DefaultRuntime");
WorkflowInstance instance;
instance = runtime1.CreateWorkflow(typeof(SimpleWorkflow));
Console.WriteLine("Setting up workflow from thread {0}",
Thread.CurrentThread.ManagedThreadId);
instance.Start();
ManualWorkflowSchedulerService scheduler;
scheduler = runtime1.GetService<ManualWorkflowSchedulerService>();
scheduler.RunWorkflow(instance.InstanceId);
instance = runtime2.CreateWorkflow(typeof(SimpleWorkflow));
instance.Start();
This code initializes each runtime by passing in a configuration section name. The primary difference in this code is how we obtain a reference to the manual scheduling service. Since we didn't create the instance explicitly, we need to ask the runtime for a reference. The generic GetService method of the WorkflowRuntime class will find and return the service.
Scheduling Parameters
Each scheduling service has a parameter to tweak it's behaviour. The manual scheduler has a useActiveTimers parameter we can set in the configuration file, or pass as a parameter to the service's constructor. When useActiveTimers is false (the default), the host is responsible for resuming workflows after any DelayActivity expires. When the parameter is true, the service will setup a background thread and use in-memory timers to resume workflow execution automatically.
The default scheduler has a maxSimultaneousWorkflows parameter. This parameter controls the maximum number of workflow instances running in the thread pool. The default value on a uni-processor machine is 5, and on a multi-processor machine is 5 * Environment.ProcessorCount * 0.8.
The processes-wide CLR thread pool has an upper limit on the number of worker threads it will create. The default maximum is 25 * the number of processors on the machine. For applications running a high volume of workflows, tweaking the maxSimultaneousWorkflows parameter might be necessary to achieve a balance between workflow throughput and the availability of free threads in the thread pool.
Choosing a Scheduling Service
Choosing the right scheduling service for an application is important. Most smart client applications will work well with the default scheduling service. Applications written with Windows Forms and Windows Presentation Foundation technologies will want to execute workflows asynchronously on thread pool threads and keep the user interface responsive.
Server-side applications generally work differently. A server application wants to process the maximum number of client requests using as few threads as possible. The ASP.NET runtime in web applications and web services already processes HTTP requests using threads from the thread pool. The asynchronous execution of workflows using the default scheduler would only tie up an additional thread per request. Server side applications will generally want to use the manual scheduler and explicitly select a thread for workflow execution.
Persistence Services
Persistence services solve the problems inherent in executing long-running workflows. Many business processes take days, weeks, and months to complete. We can't keep workflow instances in memory while waiting for the accountant to return from the beaches of Spain and approve an expense report.
Long-running workflows spend the majority of their time in an idle state. The workflow might be idle waiting for a Delay activity to finish, or an event to arrive in a HandleExternalEvent activity. When a persistence service is available, the runtime can persist and then unload an idle workflow. Persistence saves the state of the workflow into long-term storage. When the event finally arrives, the runtime can restore a workflow and resume processing.
The workflow runtime decides when to persist workflows, and the persistence service decides how and where to save the workflow state. The runtime will ask the persistence service to save a workflow's state when a workflow goes idle, and under the following conditions.
- When an atomic transaction inside a TransactionScope activity or CompensatableTransactionScopeActivity activity completes.
- When the host application calls the Unload or RequestPersist methods on a WorkflowInstance object.
- When a custom activity with the PersistOnClose attribute completes.
- When a CompensatableSequence activity completes.
- When a workflow terminates or completes.
The last condition might be surprising. A terminated or completed workflow can't perform any more work so there would be no need to reload the workflow. However, a persistence service can use the opportunity to clean up workflow state left behind from previous operations. A persistence service that saves workflow state into a database record, for instance, could delete the record when the workflow is finished executing.
Persistence Classes
All persistence services derive from the WorkflowPersistanceService class. This class defines abstract methods we need to implement if we write a custom persistence service. The abstract methods of the class appear in italics in figure 4. The base class also provides some concrete methods for a derived class to use. GetDefaultSerializedForm, for instance, accepts an Activity as a parameter and returns an array of bytes representing the serialized activity. To serialize an entire workflow we would need to pass the root activity of the workflow to this method.
Windows Workflow provides one persistence service out of the box - the SqlWorkflowPersistenceService . The SQL persistence service saves workflow state into a Microsoft SQL Server database and is the focus for the rest of this section.

The SqlWorkflowPersistenceService
To get started with the SQL persistence service we'll need a database. We can use an existing database, or we can create a new database using Enterprise Manager, Query Analyzer, or the new SQL Server Management Studio for SQL Server 2005. We can also use the command line sqlcmd.exe (for SQL Server 2005), or osql.exe (for SQL Server 2000).
Once a database is in place, we'll need to run the Windows Workflow SQL persistence scripts. We can find these scripts underneath the Windows Workflow installation directory. Since WF is installed as part of the .NET 3.0 runtime, the location will look like C:\WINDOWS\Microsoft.NET\Framework\v3.0\Windows Workflow Foundation\SQL\EN.
The SQL scripts are SqlPersistenceService_Schema.sql and SqlPersistenceService_Logic.sql. We need to run the schema file first. The schema file will create the tables and indexes in the database. The logic file creates a handful of stored procedures for the persistence service to use. Figure 5 demonstrates how we can setup a persistence database using sqlcmd.exe. We first create a database, and then run the two script files using the :r command of sqlcmd.exe.

SQL Persistence Service Configuration
Once we have a database with the persistence schema and logic inside, we can add the persistence service to the workflow runtime. We'll add the service declaratively using the following configuration file.
<configuration>
<configSections>
<section
name="WorkflowWithPersistence"
type="System.Workflow.Runtime.Configuration.WorkflowRuntimeSection,
System.Workflow.Runtime, Version=3.0.00000.0,
Culture=neutral, PublicKeyToken=31bf3856ad364e35"/>
</configSections>
<WorkflowWithPersistence>
<CommonParameters>
<add name="ConnectionString"
value="Data Source=(local);Initial Catalog=WorkflowDB;
Integrated Security=true"/>
</CommonParameters>
<Services>
<add
type="System.Workflow.Runtime.Hosting.SqlWorkflowPersistenceService,
System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral,
PublicKeyToken=31bf3856ad364e35"
UnloadOnIdle="true"
/>
</Services>
</WorkflowWithPersistence>
</configuration>
We've added the database connection string under <CommonParameters>. This will allow us to share the connection string with other services that require database connectivity. The SqlWorkflowPersistenceService appears underneath the <services> node. There are parameters available to fine-tune the behaviour of the service. We've attached one parameter in this example - the UnloadOnIdle parameter. The available parameters are shown in the table below.
| Parameter Name | Description |
| EnableRetries | When true, the service will retry failed database operations up to 20 times or until the operation completes successfully. The default is false. |
| LoadIntervalSeconds | How often the service will check for expired timers. The default is 120 seconds. |
| OwnershipTimeoutSeconds | When the persistence service loads a workflow, it will lock the workflow record for this length of time (important when multiple runtimes share the same persistence database). The default value is TimeSpan.MaxValue. |
| UnloadOnIdle | When true, the service will persist idle workflows. The default is false. |
Running With Persistence
To see the persistence service in action, let's use the following workflow definition.
x:Class="chapter6_runtime.WorkflowWithDelay"
x:Name="WorkflowWithDelay"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/workflow">
<CodeActivity x:Name="codeActivity1"
ExecuteCode="codeActivity_ExecuteCode" />
<DelayActivity x:Name="delayActivity1"
TimeoutDuration="00:00:10" />
<CodeActivity x:Name="codeActivity2"
ExecuteCode="codeActivity_ExecuteCode" />
</SequentialWorkflowActivity>
We have a Delay activity between two Code activities. The delay will idle the workflow for 10 seconds. The ExecuteCode events of both Code activities reference the same event handler in our code-behind class, listed below.
{
private void codeActivity_ExecuteCode(object sender, EventArgs e)
{
CodeActivity activity = sender as CodeActivity;
Console.WriteLine("Hello from {0}", activity.Name);
}
}
Next, we'll put together a host to run the workflow. We'll subscribe to various events and print message to track the progress of our workflow.
{
public static void Run()
{
using (WorkflowRuntime runtime =
new WorkflowRuntime("WorkflowWithPersistence"))
using (AutoResetEvent reset =
new AutoResetEvent(false))
{
runtime.WorkflowCompleted += delegate { reset.Set(); };
runtime.WorkflowTerminated += delegate { reset.Set(); };
runtime.WorkflowAborted += delegate { reset.Set(); };
runtime.WorkflowPersisted +=
new EventHandler<WorkflowEventArgs>(runtime_WorkflowPersisted);
runtime.WorkflowLoaded +=
new EventHandler<WorkflowEventArgs>(runtime_WorkflowLoaded);
runtime.WorkflowUnloaded +=
new EventHandler<WorkflowEventArgs>(runtime_WorkflowUnloaded);
runtime.WorkflowIdled +=
new EventHandler<WorkflowEventArgs>(runtime_WorkflowIdled);
WorkflowInstance instance;
instance = runtime.CreateWorkflow(typeof(WorkflowWithDelay));
instance.Start();
reset.WaitOne();
}
}
static void runtime_WorkflowIdled(object sender, WorkflowEventArgs e)
{
Console.WriteLine("Workflow {0} idled",
e.WorkflowInstance.InstanceId);
}
static void runtime_WorkflowUnloaded(object sender, WorkflowEventArgs e)
{
Console.WriteLine("Workflow {0} unloaded",
e.WorkflowInstance.InstanceId);
}
static void runtime_WorkflowLoaded(object sender, WorkflowEventArgs e)
{
Console.WriteLine("Workflow {0} loaded",
e.WorkflowInstance.InstanceId);
}
static void runtime_WorkflowPersisted(object sender, WorkflowEventArgs e)
{
Console.WriteLine("Workflow {0} persisted",
e.WorkflowInstance.InstanceId);
}
}
When we run the above code, we'll see the output in figure 6.

The first Code activity runs and the prints a message to the screen. The Delay is going block the workflow. The runtime will see the workflow has no work to perform and raise the WorkflowIdled event. The runtime also sees there is a persistence service available, and the service has specified UnloadOnIdle . The runtime asks the persistence service to save the state of the workflow, and then unloads the workflow instance. When the delay timer expires, the runtime uses the persistence service to reload the workflow instance and resumes the workflow's execution.
When the SQL persistence service reloads the workflow, the service will set a flag in the database to mark the instance as locked. If another persistence service in another process or on another machine tries to load the locked workflow instance, the service will raise an exception. The lock prevents this workflow instance from executing twice in two different runtimes. The lock is released when the workflow persists again, or when the lock timeout (specified by OwnershipTimeoutSeconds) expires.
When the workflow completes, the runtime will again ask the persistence service to persist the workflow. The SqlWorkflowPersistenceService will inspect the state of the workflow and see the workflow is finished executing. The service will delete the previously saved state record instead of saving state. The database activity takes place in the InstanceState table of the persistence database.
Persistence and Serialization
There are two types of serialization in Windows Workflow. The runtime provides the WorkflowMarkupSerializer class to transform workflows into XAML. There is no need for the mark-up serializer to save the state, or data inside of a workflow. The goal of the mark-up serializer is to produce a workflow definition in XML for design tools and code generators.
Persistence services, on the other hand, use the GetDefaultSerializedForm method of the WorkflowPersistenceService base class. This method calls the public Save method of the Activity class, and the Save method uses a BinaryFormatter object to serialize a workflow. The binary formatter produces a byte stream, and the WorkflowPersistenceService runs the byte stream through a GZipStream for compression. The goal of binary serialization is to produce a compact representation of the workflow instance for long-term storage. There are two types of serialization in Windows Workflow because each type achieves different goals.
It's not important to understand all of the gritty serialization details. What is important to take away from the above paragraph is that the runtime uses the BinaryFormatter class from the base class library when persisting workflows. We need to keep this in mind if we write a workflow like the following.
{
Bug _bug = new Bug();
}
class Bug
{
private Guid _id;
public Guid BugID
{
get { return _id; }
set { _id = value; }
}
}
Let's assume this workflow has a Delay activity inside, just as in our previous example. This workflow also includes a private Bug object. Although we don't do anything interesting with the bug object, it will change our persistence behaviour. If we run the workflow without a persistence service, the workflow should complete successfully. If we run the workflow with a persistence service, we'll see an exception similar to "Type Bug is not marked as serializable".
The BinaryFormatter will attempt to serialize every piece of state information inside of our workflow, including a custom object like our Bug object. When any object formatter comes across an object it needs to serialize, it first looks to see if there is a surrogate selector registered for the object's type. If no surrogate selector is available, the formatter checks to see if the Type is marked with the Serializable attribute. If neither of these conditions are met, the formatter will give up and throw an exception. Since we own the Bug class, we can decorate the Bug class with a Serializable attribute and avoid the exception.
class Bug
{
private Guid _id;
public Guid BugID
{
get { return _id; }
set { _id = value; }
}
}
If some third party owns the bug class, we can write a surrogate selector for serialization, which is beyond the scope of this article (see the SurrogateSelector class in the System.Runtime.Serialization namespace).
If there is a field that we don't need to serialize and restore with the workflow instance, we can tell the formatter to skip serialization with the NonSerialized attribute. The Bug object in the code below won't exist in the persisted form of the workflow. When the runtime reloads the workflow after a persistence point, the _bug field will be left unassigned.
Bug _bug = new Bug();
A persistence service stores the state of a workflow and allows us to have workflows that survive machine restarts and run for months at a time. However, a persistence service cannot tell us what happened during the execution of a workflow, or how far along a workflow has progressed. Our next topic - tracking services, will give us this information.
Tracking Services
Windows Workflow provides extensible and scalable tracking features to capture and record information about workflow execution. A tracking service uses a tracking profile to filter the information it receives about a workflow. The WF runtime can send information about workflow events, activity state changes, rule evaluations, and our own custom instrumentation data. The tracking service decides what it will do with the data it receives. The service could write tracking data to a log file, or save the data in a database. The tracking service can participate in transactions with the workflow runtime to ensure the information it records is consistent and durable.
Tracking information sounds like a useful feature for system administrators who want to analyze resource usage, but there are also tremendous business scenarios for tracking information. For example, a company could use recorded tracking information to count the number of open invoices, or the average time for invoices to close. By measuring the tracking information, a business could improve its processes.
Tracking Classes
All tracking services derive from a TrackingService base class. This class defines the API for working with tracking profiles and tracking channels . As we mentioned earlier, a tracking profile defines and filters the type of information we want to receive from the runtime. A tracking channel is a communications conduit between the workflow runtime and the tracking service. The runtime will ask the service to give it a tracking channel based on profile information. Once the runtime has an open channel, it sends information to the service via the channel.
Windows Workflow provides one implementation of a tracking service with the SqlTrackingService class. The SqlTrackingService writes the tracking information it receives to a SQL Server database. The SqlTrackingService also stores tracking profiles in the database.
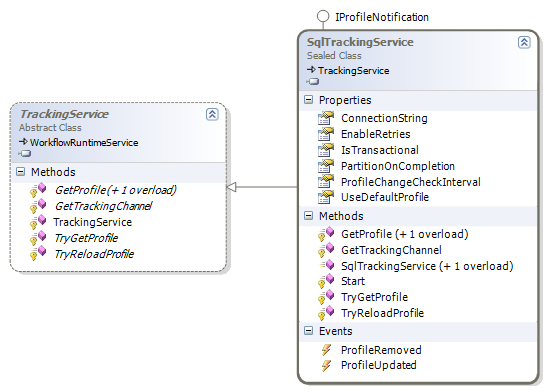
Just as we needed a schema for the SQL persistence service, we'll need to install the schema for the SQL tracking service. We can create the tracking schema in the same database as the persistence schema. The scripts to create the tracking schema are underneath the same directory as the persistence scripts (typically C:\WINDOWS\Microsoft.NET\Framework\v3.0\Windows Workflow Foundation\SQL). The scripts are Tracking_Schema.sql, and Tracking_Logic.sql. We must run the schema file before the logic file. Using the command line tool to run the scripts would look like figure 8.

Tracking Configuration
We can configure a tracking service into our runtime either programmatically or with the application configuration file. The following configuration file will load the SQL tracking service with default parameters.
<configuration>
<configSections>
<section
name="WorkflowWithTracking"
type="System.Workflow.Runtime.Configuration.WorkflowRuntimeSection,
System.Workflow.Runtime, Version=3.0.00000.0,
Culture=neutral, PublicKeyToken=31bf3856ad364e35"/>
</configSections>
<WorkflowWithTracking>
<CommonParameters>
<add name="ConnectionString"
value="Data Source=(local);Initial Catalog=WorkflowDB;
Integrated Security=true"/>
</CommonParameters>
<Services>
<add
type="System.Workflow.Runtime.Tracking.SqlTrackingService,
System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral,
PublicKeyToken=31bf3856ad364e35"
/>
</Services>
</WorkflowWithTracking>
</configuration>
The parameters we can pass to the service are listed in the table below.
| Name | Description |
| ConnectionString | The connection string to the tracking database. |
| EnableRetries | When true, the service will retry failed database operations up to 20 times or until the operation completes successfully. The default is false |
| IsTransactional | When true, the service will participate in transactions with the workflow runtime and other services, like the persistence service. The default is true. |
| PartitionOnCompletion | For high uptime and scalability, the partitioning feature periodically creates a new set of tables to store information about completed workflow instances. The default value is false. |
| ProfileChangeCheckInterval | The service caches tracking profiles but will periodically poll to see if there is a change. The default poll interval is 1 minute. |
| UseDefaultProfile | When true, the service will return a default tracking profile if no profile is defined. The default is true. |
Running With Tracking
With the tracking service added in the configuration file, there is nothing special we need to do at runtime. The code we use to run a workflow with tracking is the same as it has always been.
new WorkflowRuntime("WorkflowWithTracking"))
using (AutoResetEvent reset = new AutoResetEvent(false))
{
runtime.WorkflowCompleted += delegate { reset.Set(); };
runtime.WorkflowTerminated += delegate { reset.Set(); };
WorkflowInstance instance;
instance = runtime.CreateWorkflow(typeof(SimpleWorkflow));
instance.Start();
reset.WaitOne();
DumpTrackingEvents(instance.InstanceId);
}
When the program finishes we'll have a great deal of information recorded across several tables in our SQL Server tracking database. We can use some handwritten queries to examine the tracking information, or we can use one of many views the tracking schema installs in the database. There is also a complete object model for us to query tracking information programmatically. The classes we can use are shown in figure 9.

The SqlTrackingWorkflowInstance class gives us access to tracking information about a specific workflow instance. The ActivityEvents property of the class will return a list of ActivityTrackingRecord objects. Likewise, the WorkflowEvents property will return WorkflowTrackingRecord objects, and the UserEvents property will return UserTrackingRecord objects (which are custom events we can define). Notice the breadth of information includes time stamps, arguments, and status codes. The class even includes a WorkflowDefinition property that will return a XAML definition of the workflow. This feature can be useful for auditing workflows that use dynamic updates or that we customize for each client.
The code below makes use of these classes to retrieve a subset of the tracking information. Given a connection string and a workflow instance ID, the SqlTrackingQuery class can return a SqlTrackingWorkflowInstance object, which gives us access to all the records. The connection string we can read from the application configuration file, while the instance ID we will receive as a parameter.
{
WorkflowRuntimeSection config;
config = ConfigurationManager.GetSection("WorkflowWithTracking")
as WorkflowRuntimeSection;
SqlTrackingQuery query = new SqlTrackingQuery();
query.ConnectionString =
config.CommonParameters["ConnectionString"].Value;
SqlTrackingWorkflowInstance trackingInstace;
query.TryGetWorkflow(instanceID, out trackingInstace);
if (trackingInstace != null)
{
Console.WriteLine("Tracking Information for {0}", instanceID);
Console.WriteLine(" Workflow Events");
foreach(WorkflowTrackingRecord r in trackingInstace.WorkflowEvents)
{
Console.WriteLine(" Date: {0}, Status: {1}",
r.EventDateTime, r.TrackingWorkflowEvent);
}
Console.WriteLine(" Activity Events");
foreach (ActivityTrackingRecord r in trackingInstace.ActivityEvents)
{
Console.WriteLine(" Activity: {0} Date: {1} Status: {2}",
r.QualifiedName, r.EventDateTime, r.ExecutionStatus);
}
}
}
The output of this code is shown in figure 10.

Running one simple workflow produced a vast amount of tracking information (we've seen only a subset in this example). The SQL tracking service provided a default tracking profile that took all the information the runtime produced. If we only want to track specific pieces of information, we'll need a custom tracking profile.
Tracking Profiles
When the workflow runtime creates a new workflow instance, it will call TryGetProfile on each running tracking service and pass the workflow instance as a parameter. If the tracking service wants to receive tracking information about the workflow, it returns a TrackingProfile object. The runtime filters the tracking information it sends to the service using track points defined in the profile.The classes involved in building a tracking profile are shown in figure 11.

Let's say we don't want to track the individual activities inside a workflow. Instead, we want to track just information about the workflow itself. We'll need to define a create a new TrackingProfile object and populate the WorkflowTrackPoints property. We will leave the ActivityTrackPoints and UserTrackPoints properties empty.
profile.Version = new Version("1.0.0");
WorkflowTrackPoint workflowTrackPoint = new WorkflowTrackPoint();
Array statuses = Enum.GetValues(typeof(TrackingWorkflowEvent));
foreach (TrackingWorkflowEvent status in statuses)
{
workflowTrackPoint.MatchingLocation.Events.Add(status);
}
profile.WorkflowTrackPoints.Add(workflowTrackPoint);
string profileAsXml = SerializeProfile(profile);
UpdateTrackingProfile(profileAsXml);
A tracking profile needs a version. Tracking services will cache profiles to avoid re-fetching them each time the runtime asks for the profile. We need to change the version if we update a profile for the tracking service to recognize the update.
The code above populates the WorkflowTrackPoints collection with the workflow event types we want to record. By using Enum.GetValues on the TrackingWorkflowEvent enumeration, we will get all possible events, which includes Started, Completed, Persisted, and Terminated, among others.
Once we've populated the TrackingProfile object, we need to update the profile in the tracking service. The first step in the update process is to serialize the profile object to XML. The TrackingProfileSerializer will perform the serialization for us.
{
TrackingProfileSerializer serializer;
serializer = new TrackingProfileSerializer();
StringWriter writer = new StringWriter(new StringBuilder());
serializer.Serialize(writer, profile);
return writer.ToString();
}
The SQL tracking service stores profiles as XML in the TrackingProfile table (except for the default tracking profile, which the service keeps in the DefaultTrackingProfile table). The best approach for updating and inserting into this table is to use the UpdateTrackingProfile stored procedure. When we add a new tracking profile, we must associate the profile with a workflow type. We will the new profile with our SimpleWorkflow workflow.
{
WorkflowRuntimeSection config;
config = ConfigurationManager.GetSection("WorkflowWithTracking")
as WorkflowRuntimeSection;
using (SqlConnection connection = new SqlConnection())
{
connection.ConnectionString =
config.CommonParameters["ConnectionString"].Value;
SqlCommand command = new SqlCommand();
command.Connection = connection;
command.CommandType = CommandType.StoredProcedure;
command.CommandText = "dbo.UpdateTrackingProfile";
command.Parameters.Add(
new SqlParameter("@TypeFullName",
typeof(SimpleWorkflow).ToString()));
command.Parameters.Add(
new SqlParameter("@AssemblyFullName",
typeof(SimpleWorkflow).Assembly.FullName));
command.Parameters.Add(
new SqlParameter("@Version","1.0.0"));
command.Parameters.Add(
new SqlParameter("@TrackingProfileXml", profileAsXml));
connection.Open();
command.ExecuteNonQuery();
}
}
There are four parameters to the UpdateTrackingProfile stored procedure. The @TypeFullName parameter needs the full type name (including namespaces) of the workflow to associate with this profile. Likewise, the @AssemblyFullName parameter will need the full name of the assembly containing the associated workflow's definition. The @Version parameter should contain the version of the tracking profile, and the @TrackingProfileXml should contain the XML representation of a TrackingProfile object.
With the tracking profile in the database, we will record different information when we run our simple workflow (other workflows will continues to use the default tracking profile which records every event). Rerunning our program shows the output in figure 12. We are still recording workflow tracking events, the new profile doesn't record any activity events.

Data Maintenance
The SQL Tracking service provides a partitioning feature to move tracking information out of the primary set of tracking tables and into a set of partitioned tracking tables. A new set of partition tables will be created at defined intervals. The SetPartitionInterval stored procedure configures the partitioning interval. The default interval is monthly, but other valid values include daily, weekly, and yearly. The tables will contain the date as part of the table name.
There are two approaches to partitioning. Automatic partitioning is configured by setting the PartitionOnCompletion parameter of the SQL tracking service to true. Automatic partitioning will move tracking information into a partition as soon as a workflow completes. Automatic partitioning is good for applications that don't have any down time, but will add some overhead as completed workflow records constantly shuffle into partitions.
We can also use manual partitioning by running the PartitionCompletedWorkflowInstances stored procedure. The stored procedure will move the tracking records for completed workflows into partitioned tables. For applications with some down time we could schedule this stored procedure to run during non-peak hours.
Persistence and Tracking Together
The SQL persistence and SQL tracking services work to provide durable storage for workflow state and workflow tracking information. However, they don't quite work together. Specifically, each service will operate using different connections to the database. A workflow runtime with both services present will use more connections then necessary. Additional overhead will arise if the tracking service is transactional. When transactions span multiple connections, the Microsoft Distributed Transaction Coordinator (MSDTC) becomes involved and manages the transaction. MSDTC carries some overheard.
WF provides an optimization for applications using both the SQL persistence and SQL tracking services with the 46 character long SharedConnectionWorkflowCommitWorkBatchService class. The service allows the two SQL services to share a connection if the connection string for both is the same.
Shared Connection Configuration
The configuration file below configures both SQL workflow services and the shared connection service. Since we define the connection string parameter in the CommonParameters section, all the services will use the same connection string.
<configuration>
<configSections>
<section
name="WorkflowConfiguration"
type="System.Workflow.Runtime.Configuration.WorkflowRuntimeSection,
System.Workflow.Runtime, Version=3.0.00000.0,
Culture=neutral, PublicKeyToken=31bf3856ad364e35"/>
</configSections>
<WorkflowConfiguration>
<CommonParameters>
<add name="ConnectionString"
value="Data Source=(local);Initial Catalog=WorkflowDB;
Integrated Security=true"/>
</CommonParameters>
<Services>
<add
type="System.Workflow.Runtime.Tracking.SqlTrackingService,
System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral,
PublicKeyToken=31bf3856ad364e35"
/>
<add
type="System.Workflow.Runtime.Hosting.SqlWorkflowPersistenceService,
System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral,
PublicKeyToken=31bf3856ad364e35"
UnloadOnIdle="true"
/>
<add
type=
"System.Workflow.Runtime.Hosting.SharedConnectionWorkflowCommitWorkBatchService,
System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral,
PublicKeyToken=31bf3856ad364e35" />
</Services>
</WorkflowConfiguration>
</configuration>
We don't need to change our application, as the shared connection service will coordinate behind the scenes with the other runtime services.
Summary
The Windows Workflow runtime is flexible and extensible. We can customize the runtime by adding services to meet our application's needs. Scheduling services allow us to control the assignment of workflow to threads. Persistence services allow us to save the state of workflows. Tracking services allow us to monitor, record, and measure workflow execution. Windows Workflow exposes diagnostic tracing information with the .NET tracing API. A workflow host can add these services with code, or using an application configuration file.
by K. Scott Allen
Please leave feedback on my blog.


 Subscribe
Subscribe
 Twitter
Twitter
 Search
Search
 About
About
 Learn C#
Learn C#